Организация распределенной потоковой обработки данных: разделение на подпотоки и восстановление после сбоев
←
→
Транскрипция содержимого страницы
Если ваш браузер не отображает страницу правильно, пожалуйста, читайте содержимое страницы ниже

Организация распределенной потоковой
обработки данных: разделение на
подпотоки и восстановление после
сбоев
Артем Трофимов, руководитель группы разработки распределенной
вычислительной платформы для машинного обучения ʎzy, Яндекс
Научный руководитель: Борис Асенович Новиков
1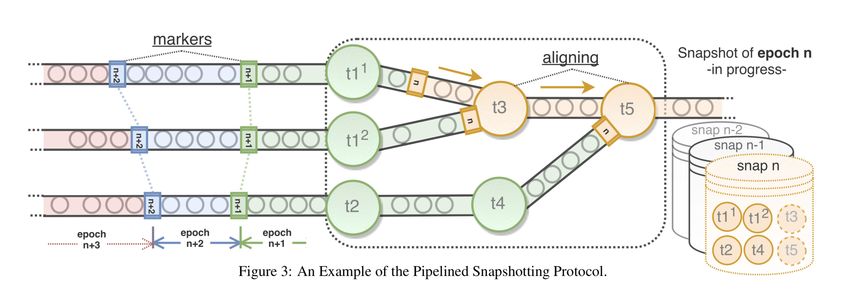
Потоковая vs пакетная обработка
• Бесконечные данные
• Бесконечные вычисления
• Требования к задержке*
*не отменяющие требования к пропускной способности
2
Где применяется потоковая обработка?
• Онлайн-аналитика
• Краткосрочная персонализация
• Онлайн-обучение и применение моделей
3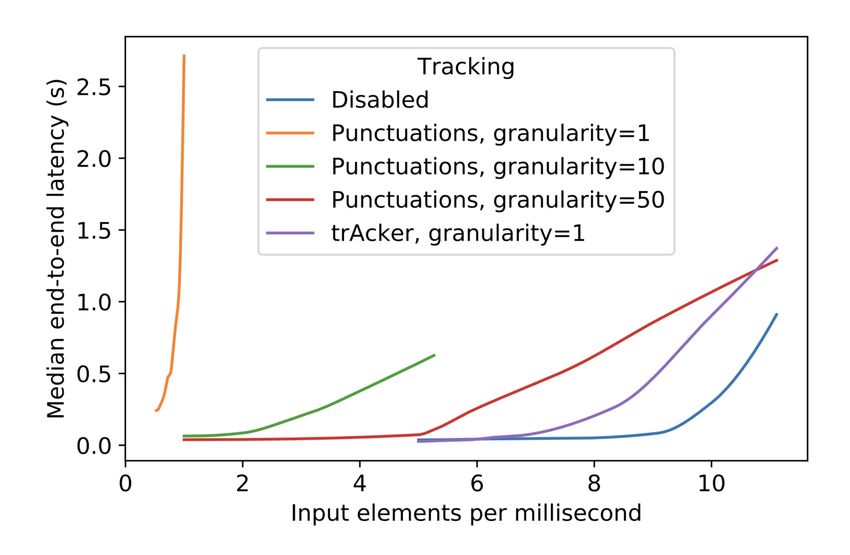
Модель потоковой обработки
Источник данных Сток данных
item item item Система item item item
обработки
4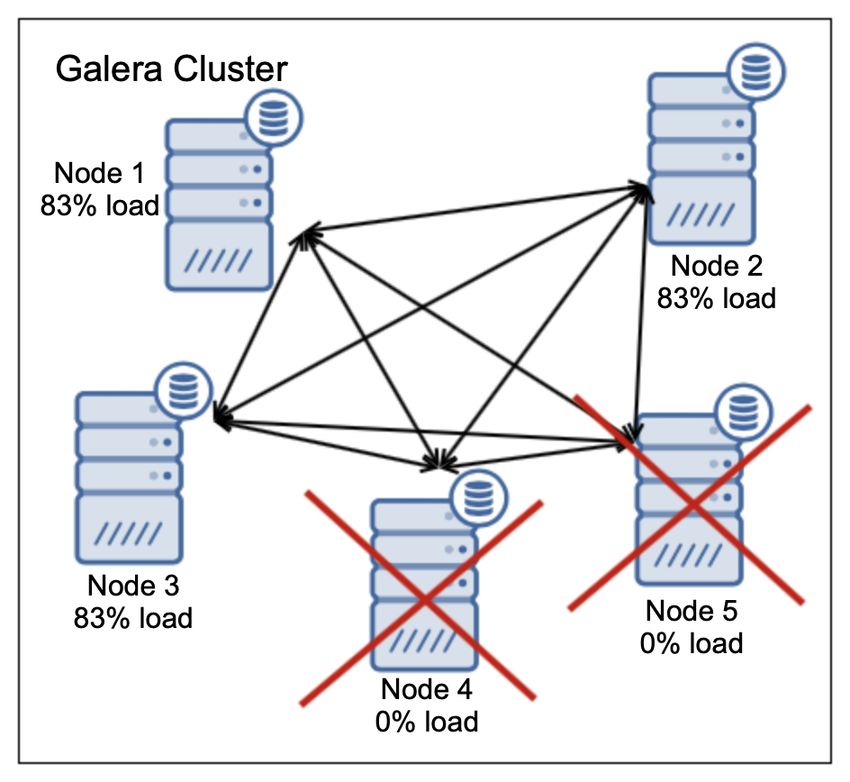
Потоковые операции
• Stateless
• Stateful in
OP
out
in state out state’
OP
5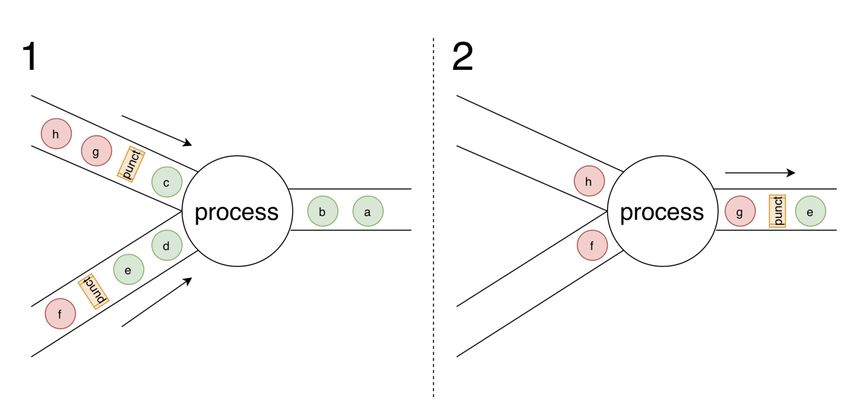
Логический граф исполнения
• Вершины - операции
• Ребра - связи между операциями source op1 op2 op3 sink
• Перед каждой операцией можно
задать шардирование (например,
по ключу)
Система
обработки
6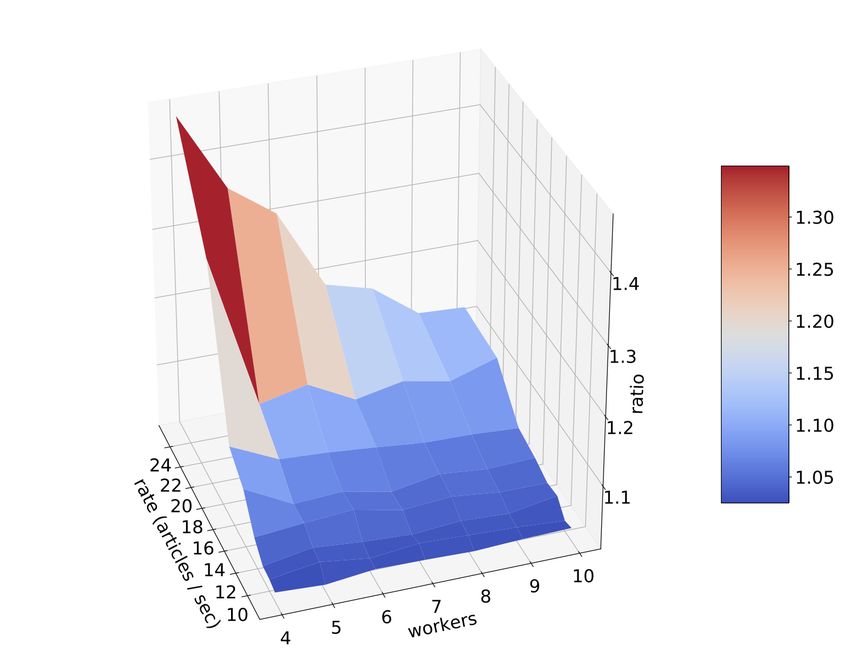
Физический граф исполнения
7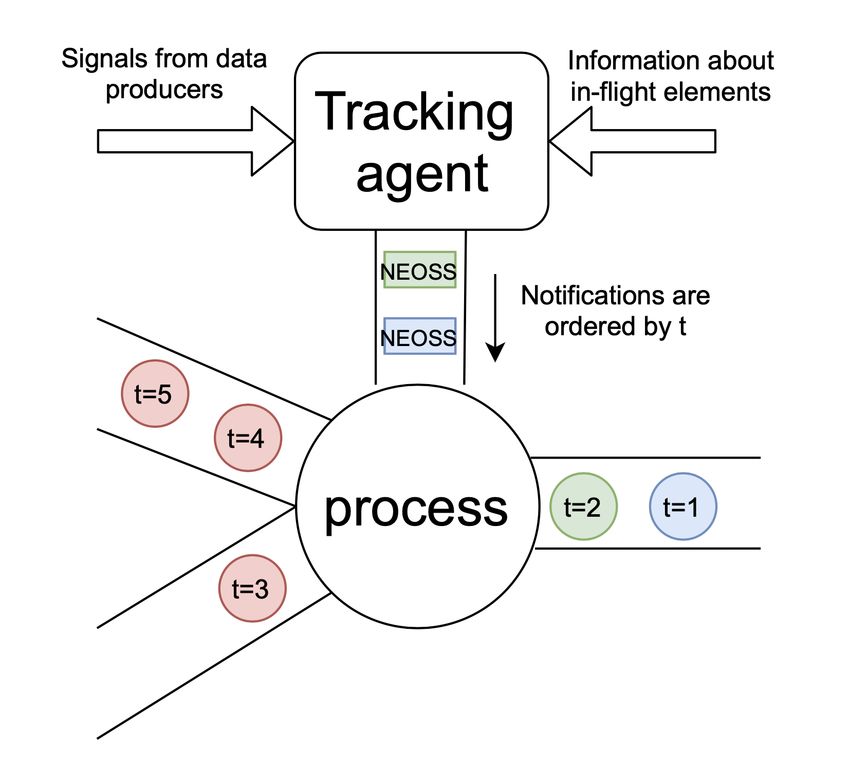
Пример: классификация текстов
Логический граф
8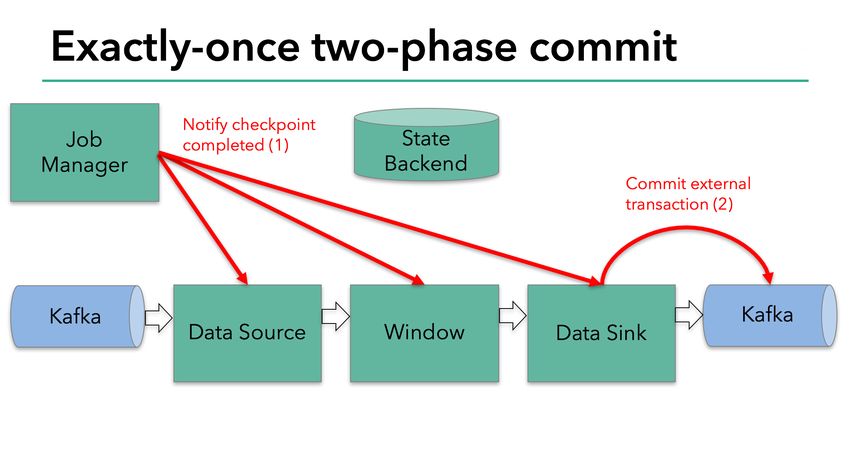
Пример: классификация текстов
Физический граф
9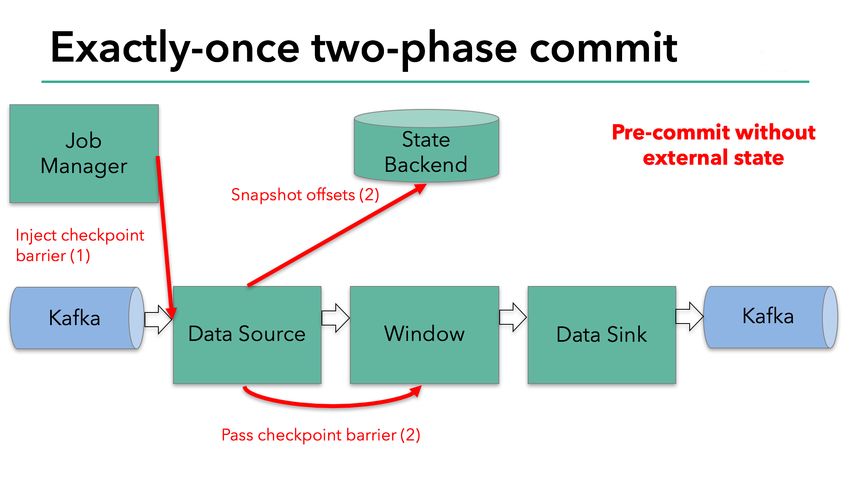
Про эксперименты в докладе
• Используется описанный граф,
если не указано обратное
• По умолчание использовалось
10 вычислительных узлов
• Для экспериментов про
подпотоки использовался
синтетический граф из 10
операций
10Потоковые сложности
• Бесконечный вход - бесконечный выход
‣ Как чистить состояние?
‣ Когда выпускать результат агрегации?
• Вычислительные узлы могут падать
‣ Как восстановить состояние?
‣ Как обеспечить согласованные результаты?
11Часть 1: проблема бесконечности потока
• Пример: HashJoin двух потоков -
состояние увеличивается с
каждым элементом
• В какой момент выпускать
резульат?
https://www.reddit.com/r/itookapicture/comments/
7r9nqc/itap_of_two_streams_joining_together/
12Подпотоки
• Пусть на элементах потока задан
предикат p(x)
• Подпоток - все элементы,
удовлетоворяющие p(x)
• Интересен конец подпотока - можно
чистить состояние/отдавать
результат
• Одновременно может быть
множество подпотоков
13Окна - подпотоки по времени
• Разбиваем поток на окна по
времени
• Для каждого окна считаем
агрегацию и выпускаем результат
https://www.oreilly.com/radar/the-world-beyond-batch-
streaming-101/
14Виды окон
• Непересекающиеся
• Скользящие
• Сессионные
https://www.oreilly.com/radar/the-world-beyond-batch-
streaming-101/
15Как определить конец окна?
Источник данных
item EOW item item Система
обработки
16Пунктуации - способ доставки сигнала до операций
p
p
p
p
17Свойства пунктуаций
• Просты в реализации: используют
сетевые каналы обработки
• Могут влиять на пропускную
способность системы
• Не работают в циклических графах
• Сложность по трафику O(K||P^2||) из-
за бродкастов, K - кол-во
подпотоков, P - кол-во
вычислительных узлов
Akidau T. et al. Watermarks in Stream
Processing Systems: Semantics and
Comparative Analysis of Apache Flink
and Google Cloud Dataflow. VLDB 2021
18Чем это отличается от микро-батчинга?
• В случае потока вычисления могут быть уже сделаны, нужно дождаться
момента, когда их можно отдать
• В случае микро-батчинга следующая стадия (операция) обработки не
начинается, пока предыдущая не обработала весь батч
https://subscription.packtpub.com/book/big-data-and-
business-intelligence/9781787126497/9/ch09lvl1sec58/
understanding-micro-batching
19Tracker: альтернативный подход к доставке сигнала
• Сигналы от источников
направляются в отдельного агента
• Этот же агент агрегирует
информацию про элементы в
потоке от всех операций
• Уведомления об окончании
подпотока рассылаются агентом
Kuralenok, I. E., Trofimov, A., Marshalkin, N., & Novikov, B.
(2018, September). Deterministic Model for Distributed
Speculative Stream Processing. In European Conference on
Advances in Databases and Information Systems (pp.
233-246). Springer, Cham.
20Tracker: реализация
• Каждая операция присваивает
каждому выходному элементу
случайное число и отправляет его в
Tracker (вместе с информацией про
предикат) после отправки по потоку
• Каждая операция, которая
принимает элемент отправляет то
же число в Tracker
• Tracker агрегирует числа по
предикату и применяет к ним XOR,
если он стал 0 - подпоток
закончился
21Tracker: свойства
• Линейная сложность по
трафику - O(K||P||)
• XOR коммутирует - можно
делать предварительную
агрегацию на машинках
• Поддерживаются циклические
графы
• Достаточно просто сделать
распределенную реализацию
агента
22Tracker: накладные расходы на систему
23Tracker: end-to-end эксперименты
24Часть 2: проблемы восстановления и согласованности
• Вычислительные узлы могут
отказывать
• Пользователь не должен
наблюдать падения (по
результатам)
https://severalnines.com/database-blog/clustered-database-node-failure-and-its-impact-high-availability
25Проблема восстановления состояния
• Порядок обработки элементов
может быть
недетерминированным
• Операции могут быть
некоммутативными
• Хочется, чтобы пользователь не
наблюдал падения (по
результатам)
26Гарантии “доставки”
• At-most-once
• At-least-once
• Exactly-once
27Гарантии доставки - про согласованность выхода
• Пусть есть идеальная стратегия восстановления, которая может
восстановить состояние операций и все in-flight элементы
• Пусть B - множество выходных элементов, которые система выпускает с
идеальной стратегией восстановления
• At most once гарантирует, что выход будет состоять из подмножества B
• At least once гарантирует, что выход будет состоять из множества B с
повторениями (мультимножества)
• Exactly once гарантирует, что выход будет состоять из множества B
28Две модели восстановления
• Модель 1: контролируем каналы
внутри системы
• Модель 2: контролируем каналы
на входе/выходе
• Допущение: умеем вычитывать
данные из источника по метке
29Модель 1 на примере MillWheel: сохранение состояния
in out
• У каждого элемента в системе есть
уникальный ID 1 4
• Операция проверяет, приходил ли ей op1 op2
ACK ACK
элемент с таким ID, если да - он
3 5
отфильтровывается
out
• Выполняется пользовательский код,
вычисляется новое состояние 2 state
• В рамках одной транзакции сохраняется:
ID входного элемента, новое состояние in ID
(или diff), выходные элементы
• Отправляется ACK предыдущей
операции за входной элемент
30Модель 1 на примере MillWheel: восстановление
• Упавшая операция out out
восстанавлиается и перепосылает
сохраненные выходные элементы 3 4
за которые нет ACK-а op1 op2
• Предыдущая операция не
дожидается ACK от упавшей и
перепосылает выход out
2 out 1
• Если упавшая операция на самом state
деле успела обработать вход, но
не успела послать ACK, то входной
элемент отфильтруется
дедупликатором
31Свойства модели 1
• Локальное восстановление операций без stop
the world
• Накладные расходы размазываются по
операциям, что хорошо: не все операции stateful
• Требуется очень эффективное хранилище для
состояния
32Модель 2 на примере Flink: сохранение состояния
• Основная идея - поток разделяется на
непересекающиеся подпотоки (эпохи), для каждой эпохи
создается снепшот, на который можно откатиться
• Раз в N элементов/минут в источник инъектируется
специальный элемент - барьер (ничего не напоминает? :)
и запоминается воотвествующая метка во входном
потоке
• Когда барьер приходит в операцию, канал, по которому
он пришел блокируется
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/stateful-stream-processing/
• Когда барьеры пришли со всех каналов состояние
сохраняется в “надежное”™ хранилище
• Когда барьер доходит до всех стоков, сохраненные
состояния помечаются как готовый снепшот
Carbone P. et al. Lightweight asynchronous snapshots for distributed dataflows //arXiv preprint arXiv:1506.08603. – 2015.
33Модель 2 на примере Flink: сохранения состояния фаза 1
https://flink.apache.org/features/2018/03/01/end-to-end-
exactly-once-apache-flink.html
34Модель 2 на примере Flink: сохранения состояния фаза 2
https://flink.apache.org/features/2018/03/01/end-to-end-
exactly-once-apache-flink.html
35Barrier alignment
Carbone P. et al. State management in Apache Flink®: consistent stateful distributed stream
processing //Proceedings of the VLDB Endowment. – 2017. – Т. 10. – №. 12. – С. 1718-1729.
36Модель 2 на примере Flink: восстановление
• Операции восстанавливают
состояние из последнего
сохраненного снепшота
• У источника заново
запрашиваются элементы
после последнего барьера
37Свойства модели 2
• Stop-the-world при восстановлении
• При exactly-once элементы можно
выпускать только в момент сохранения
снепшота*
• Небольшие накладные расходы для at-least-
once (потому что это не совсем at least once)
38Свойства модели 2: зависимость задержки от периода снепшотов
39Свойства модели 2: аномалия at-least-once
• При at-least-once гарантии в
модели 1 выходные элементы
не ожидают коммита
• Если в графе есть
некоммутативная операция -
результаты могут быть
несогласованными после
падения
40Модификация модели 2: детерминированное исполнение
• Аномалия при at-least-once
возникает из-за того, что при
повторном исполнении мы можем
получить другое состояние
• Необходимость ожидать снепшот
для выпуска элементов - по той же
причине
• Можно ли сделать исполнение
детерминированным?
41Как обеспечить детерминизм?
• Можно логировать все источники
недетерминизма
• Если функции чистые -
буферизовать вход и ожидать
пунктуацию для сортировки
42Оптимистичный подход к обеспечению детерминизма
• Допустим, что все функции в
графе чистые
• Задаем порядок на входе t(x)
(например, kafka offsets)
• Если элементы пришли в
правильном порядке -
обрабатываем в обычном режиме
• Если приходит элемент вне
порядка - пересчитываем
состояние и инвалидируем
предыдущие результаты
43Состояние как элемент потока
• Любая операция с состоянием
представляется в виде
группировки с окном 2 и map
• Группировка объединяет
предыдущее состояние и
новый элемент
• Map преобразует элемент и
состояние в результат
операции и новое состояние
44Структура состояния группировки
Вход: 4,3,3,2
• Группировка хранит
элементы упорядоченные по
t(x) 0 4 4 3 7 3 10 2 12
• Выходной элемент получает t(x) = 1 t(x) = 1.1 t(x) = 7 t(x) = 7.1 t(x) = 9 t(x) = 9.1 t(x) = 10 t(x) = 10.1
t(x) наибольшего из пары
45Оптимистичный детерминизм: инвалидация элементов
• Если элемент приходит вне
порядка, то выпускаем
правильные и повторяем
неправильный с пометкой
• Инвалидирующий элемент идет
обратно в группировку по циклу
и дальше по потоку, порождая
инвалидацию в других
операциях
46Оптимистичный детерминизм: когда можно выпускать элементы?
• Поток уже разделен на микро-
эпохи, заданные порядком на
входных элементах
• Можно отдавать результат,
если в графе нет
инвалидирующих элементов за
очередную эпоху
• Определить наличие
инвалидирующих элементов
можно с помощью Tracker
47Оптимистичный детерминизм: сохранение состояния
Вход: 4,3,3,2
• Состояние операции имеет
структуру списка, упорядоченного
по заданному на входе порядку 0 4 4 3 7 3 10 2 12
• Сохранять состояние за t(x) = 1 t(x) = 1.1 t(x) = 7 t(x) = 7.1 t(x) = 9 t(x) = 9.1 t(x) = 10 t(x) = 10.1
очередную микро-эпоху можно в
фоновом процессе, когда система
уверена, что за эту эпоху не будет
инвалидирующих элементов
• Как только все операции
сохранили состояние за микро-
эпоху, система может с нее
восстанавливаться
48Оптимистичный детерминизм: восстановление состояния
• Операции восстанавливают
состояние из последнего
сохраненного снепшота
• У источника заново
запрашиваются элементы после
последнего барьера
49Оптимистичный детерминизм: свойства
• Не нужно ожидать снепшота для
выпуска элементов, достаточно
подождать пока обработаются все
невалидные элементы за квант
времени (микро-эпоху)
• Процент дополнительных
элементов не очень большой, если
система не перегружена
• Плохо подходит, если: не можем
упорядочить поток на входе, в
графе много операций с
состоянием или состояние большое
• Сохранение состояния не
блокирует операции, нет проблемы
barrier alignment
50Оптимистичный детерминизм: end-to-end эксперименты
51Как выбрать гарантию?
• Для банковских транзакций
(наверное) нужен exactly-once
• Для обучения скорее всего
достаточно at-least-once
• Для inference зависит от задачи
52Как выбрать гарантию? At least once: пример 1
53Как выбрать гарантию? At least once: пример 2
54Заключение
• С бесконечным входом работать сложно - поэтому обычно поток разбивают на подпотоки
• Стандартная техника разбиения на подпотоки - пунктуации, но с ними нужно быть
осторожными при большом количестве подпотоков и нод
• Для большого количества одновременных подпотоков лучше подходит Tracker
• Exactly-once может добавить накладные расходы (особенно на задержку), поэтому стоит
подумать, а нужна ли такая сильная гарантия
• Exactly-once = at-least-once + дедупликация, можно подумать о дедупликации на стороне
потребителя данных
• Если в потоке немного операций с состоянием и состояние небольшое - можно сделать
оптимистичный детерминизм и не ожидать снешоты для выпуска элементов
55Вы также можете почитать

















































