Алгоритм распределенного вычисления тематической центральности пользователей в социальном графе для измерения их взаимного информационного влияния ...
←
→
Транскрипция содержимого страницы
Если ваш браузер не отображает страницу правильно, пожалуйста, читайте содержимое страницы ниже
Министерство образования и науки Российской Федерации
Московский государственный университет имени М. В. Ломоносова
Механико-математический факультет
Кафедра «Компьютерная алгебра»
Аванесов Валерий Сергеевич
Выпускная квалификационная работа магистра
Алгоритм распределенного вычисления
тематической центральности пользователей в
социальном графе для измерения их взаимного
информационного влияния
An algorithm for distributed computation of topical
graph centrality of social network users for measuring
their mutual informational influence
Научные руководители:
к.ф.–м.н. Турдаков Денис Юрьевич
к.ф.–м.н. Зобнин Алексей Игоревич
Москва
2014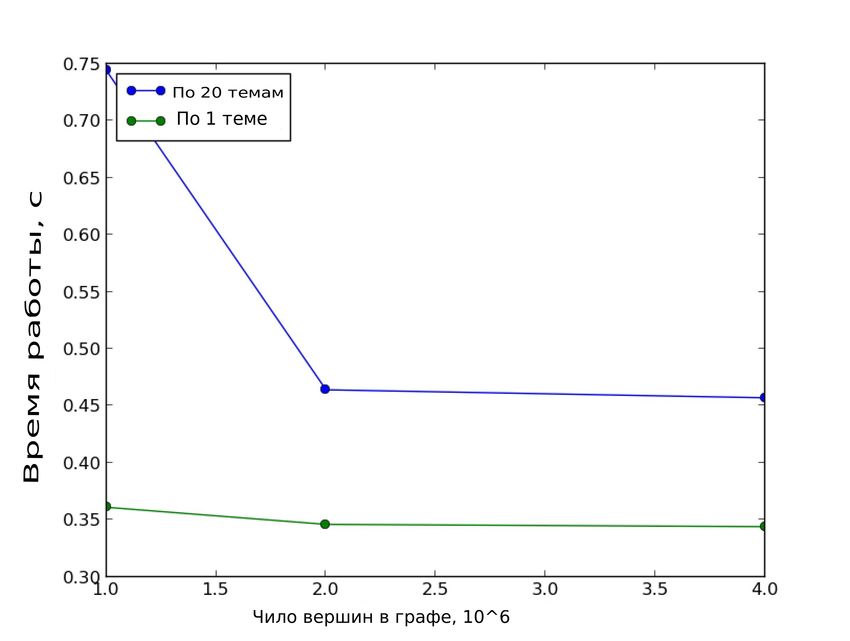
Содержание
1 Введение 5
1.1 Практическая значимость . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2 Основные определения . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3 Основные обозначения . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Постановка задачи 8
3 Обзор существующих методов 10
3.1 Тематическое моделирование . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.1.1 PLSA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.1.2 Регуляризованный PLSA . . . . . . . . . . . . . . . . . . . . . . . 11
3.1.3 Робастный PLSA . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2 Алгоритм PageRank . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.3 Агоритм измерения глобального информационного влияния TwitterRank 16
3.4 Сбор подграфа социальной сети . . . . . . . . . . . . . . . . . . . . . . . 17
3.5 Выводы . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4 Исследование и построение решения задачи 19
4.1 Оценка локального влияния . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.2 Подход с использованием машинного обучения с учителем для оценки
локального влияния . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.3 Выбранная тематическая модель . . . . . . . . . . . . . . . . . . . . . . 21
4.4 Методы ускорения обучения тематической модели . . . . . . . . . . . . 22
4.4.1 Метод получения тем по подмножеству обучающей выборки . . 23
4.4.2 Метод, основанный на поиске неслучайного начального прибли-
жения, позволяющего сократить число итераций алгоритма обу-
чения PLSA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.5 Алгоритмы определения графовой близости пары вершин . . . . . . . . 24
4.5.1 Алгоритмы нахождения максимального потока . . . . . . . . . . 25
4.5.2 Алгоритмы нахождения длины кратчайшего пути . . . . . . . . 25
24.5.3 Близость на основе сообществ . . . . . . . . . . . . . . . . . . . . 27
4.6 Алгоритм поиска сообществ пользователей . . . . . . . . . . . . . . . . . 27
4.6.1 Алгоритм SLPA . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.6.2 Применение алгоритма SLPA . . . . . . . . . . . . . . . . . . . . 28
4.7 Сбор размеченных документов . . . . . . . . . . . . . . . . . . . . . . . . 29
4.8 Методы оценки качества . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.8.1 Оценка качества работы тематической модели . . . . . . . . . . . 30
4.8.2 Оценка качества оценки информационного влияния пользовате-
лей . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.8.3 Площать под ROC-кривой . . . . . . . . . . . . . . . . . . . . . . 31
4.9 Выводы . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5 Описание практической части 33
5.1 Выбранный инструментарий . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.2 Общая схема работы . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.3 Выводы . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
6 Эксперимент 37
6.1 Описание данных . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
6.2 Экспериментальная оценка качества тематической модели . . . . . . . . 37
6.3 Экспериментальная оценка качества предсказания локальных агентов
влияния . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
6.4 Оценка производительности . . . . . . . . . . . . . . . . . . . . . . . . . 39
6.5 Оценка масштабируемости . . . . . . . . . . . . . . . . . . . . . . . . . . 40
6.6 Выводы . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
7 Заключение 43
3Аннотация
Решается задача распределенного вычисления тематической центральности
пользователей в социальном графе для измерения их взаимного информацион-
ного влияния. Рассмотрен алгоритм TwitterRank для вычисления глобального
информационного влияния пользователя. Произведено усовершенствование ал-
горитма TwitterRank, позволяющее оценивать взаимное влияние пользователей.
Написана распределенная реализация. Проанализировано качество и скорость
работы, а так же масштабируемость в распределенных системах. Результаты
подтверждены численным экспериментом на реальном подмножестве социаль-
ной сети Twitter и синтетических данных.
41 Введение
Сегодня социальные сети предоставляют огромный объем данных о взаимодействиях
между пользователями. Их анализ может позволить увеличить удобство пользова-
ния социальной сетью, эффективность рекламы и даже выявлять подготовку терак-
тов и массовых беспорядков. Одной из задач анализа взаимодействия пользователей
является измерение взаимного информационного влияния пользователей.
Информационным влиянием будем называть способность пользователя изме-
нять чье-либо поведение и/или мнение посредством распространения информации.
Причем, будем называть агентом влияния пользовтеля, изменяющего чье-либо пове-
дение и/или мнение посредством распространения информации, а пользовтеля, чье
поведение и/или мнение изменяется посредством информации, распространяемой
агентом, реципиентом. Будем подразделять агентов влияния на глобальных и ло-
кальных. Глобальный агент влияния оказывает влияние независимо от социальных
связей (напр. Альберт Эйнштейн), тогда как влияние локального агента влияния
распространяется лишь посредством социальных связей. (напр. школьный учитель
физики).
Дипломная работа посвящена решению проблемы измерения взаимного влияния
пользователей социальной сети. Предлагаемое решение основано на предположении
о том, что степень влияния одного пользователя на другого может быть выражена
через распределение интересов реципиента по темам, рангов глобального информа-
ционного агента влияния по темам, графовой близости и факте вхождения агента и
реципиента в одно сообщество. Для определения интересов пользователя использу-
ются методы тематического моделирования на сообщениях, опубликованных поль-
зователем в социальной сети, для поиска сообществ применен метод кластеризации
графов, для определения графовой близости пользователей применены методы, ос-
нованные на кратчайшем пути в графе, а так же основанные на сообществах, обра-
зуемых пользователями. Для построения выражения для взаимного влияния поль-
зователей применен эвристический интерпретируемый и легко обобщаемый подход,
а также лишенный этих достоинств, но более точный метод машинного обучения с
учителем.
В задачах анализа социальных сетей возникает проблема обработки больших
объемов данных. Для решения этой проблемы была разработана и реализована рас-
5пределенная версия алгоритма, позволяющая обрабатывать социальные сети цели-
ком. Кроме того, в ходе проделанной работы были разработаны новые методы, поз-
воляющие ускорить один из наиболее употребимых алгоритмов тематического обу-
чения. Эти методы опубликованы в трудах конференции SYRCoDIS 2014 [1].
Для тестирования алгоритма на работоспособность была проведена эксперимен-
тальная оценка качества работы всех вариантов разработанного алгоритма. Анало-
гично с методологией, описанной в работе Динга и др. [2], оценка проводилась в
предположении о том, что цитируемость агента реципиентом указывает на высокую
степень влияния.
1.1 Практическая значимость
Рекомендация пользователей.
C помощью разрабатываемой системы возможно осуществить рекомендацию
пользователю его локальных агентов влияния.
Организация списка контактов.
Разрабатываемая система позволит отсортировать список контактов пользова-
теля по степени их на него влияния.
Организация ленты пользователя.
Разрабатываемая система позволит отсортировать список сообщений друзей
пользователя (ленту пользователя) по степени влияния авторов на пользователя.
Выявление агрессивных формирований.
Разрабатываемая система может быть применена для выявления готовящихся
терактов [3] и революций. Как известно из СМИ, бесчинства на Манежной площади
2011 года были организованы посредством социальных сетей.
1.2 Основные определения
Информационное влияние – способность изменения чьего-либо поведения и/или
мнения посредством распространения информации.
Агент влияния – тот, кто изменяет чье-либо поведение собственным примером.
Глобальный агент влияния – агент, оказывающий влияние независимо от соци-
альных связей (напр. Альберт Эйнштейн).
Локальный агент влияния – агент, влияние которого распространяется исключи-
6тельно по социальным связям (напр. школьный учитель физики).
Реципиент – тот, чье поведение изменено агентом.
Социальный граф – граф, в котором вершины – пользователи социальной сети, а
ребра (возможно, ориентированные) – отношения дружбы, знакомства и т.п.
Взвешенный социальный граф – социальный граф, каждому ребру в котором
приписан вес, характеризующий степень дружбы, знакомства и т.п.
Сообщение пользователя – сообщение, опубликованное пользователем в социаль-
ной сети от своего имени.
1.3 Основные обозначения
• G = (V, E) – социальный граф
• G = (V, E, W ) – взвешенный социальный граф
Nv
• {Dvi }i=1 – сообщения пользователя v ∈ V
• Dv – конкатенация сообщений {Dvi }N
i=1 пользователя v ∈ V
v
72 Постановка задачи
Целью данной работы является исследование и разработка методов распределенно-
го вычисления тематической центральности пользователей в социальном графе для
измерения их взаимного информационного влияния.
Притом, очевидно, человек, оказывающий существенное влияние по одной теме
(например, по математике) может быть совершенно неавторитетен в другой (в фут-
боле). Потому для модели необходима возможность определять агентов влияния как
по одной теме, таки по их совокупности.
Также, задание тем аналитиками – дорогостоящая процедура. Потому, модель
должна сама извлекать темы, влияние по которым будет оцениваться. Однако, мы не
можем допустить, чтобы модель извлекала темы полностью самостоятельно. Необ-
ходимо оставить возможность в некоторой степени (см. главу 4.3) предопределить
все или часть тем.
Планируется использование этой модели человеком, причем, необходимо, что-
бы человек понимал, почему модель приняла именно такое решение. Потому, темы
должны должны быть интерпретируемы. В то же время, человек создание нетерпе-
ливое, потому система должна быть отзывчивой – быстро находить агентов влияния
для заданного реципиента.
Наиболее развитой социальной сетью (в плане количества вовлеченных людей и
обилия социальных связей) является Twitter1 . Таким образом, наша модель должна
быть способна работать с данными, полученными из этой социальной сети. Заметим,
что это влечет необходимость работать с направленными социальными графами.
Социальная сеть Twitter на текущий момент включает порядка 109 пользовате-
лей. Это влечет необходимость разработки распределенной масштабируемой реали-
зации модели.
Для достижения поставленной цели необходимо:
1. Исследовать существующие методы вычисления тематической центральности
пользователей в социальном графе для измерения их взаимного информацион-
ного влияния.
1
http://www.twitter.com
82. Разработать и реализовать последовательный алгоритм вычисления темати-
ческой центральности пользователей в социальном графе для измерения их
взаимного информационного влияния.
3. Выполнить экспериментальную оценку качества разработанного алгоритма
4. Разработать и реализовать распределенную версию этого алгоритма.
5. Выполнить экспериментальную оценку масштабируемости разработанного ал-
горитма
93 Обзор существующих методов
В этой главе описан алгоритм оценки тематической центральности TwitterRank. По-
скольку этот алгоритм является модификацией алгоритма PageRank и в существен-
ной мере опирается на методы тематического моделирования, в главе 3.1 ставится
задача тематического моделирования и проводится обзор методов решения этой за-
дачи, в главе 3.2 описывается алгоритм PageRank. В главе 3.3 описан, собственно,
алгоритм TwitterRank.
Поскольку описываемые в этой главе методы относятся к методам машинного
обучения, необходимо как-либо извлечь данные для обучения. В главе 3.4 описаны
методы сбора данных.
3.1 Тематическое моделирование
Согласно [4] задача тематического моделирования может быть формализована сле-
дующим образом.
Пусть есть набор документов D, причем, ∀d ∈ D : d = {wi }ni=1
d
, где W - алфавит,
∀wi ∈ W , nd - длина документа в словах.
Пусть также задано число тем |T |. Множество тем обозначим как T .
3.1.1 PLSA
Наиболее простой моделью является PLSA, представленная в работе Д. Хоффма-
на [5].
PLSA предполагает, что каждый документ d получен следующим образом: ге-
нерируется последовательность zdi ∼ M ult(θd· ), а затем последовательность слов
wdi ∼ M ult(ϕzi · ).
Параметрами модели являются матрицы Θ = {θdt }d∈D,t6T = {p(t|d)}d∈D,t∈T и
Φ = {ϕwt }t∈T,w∈W = {p(w|t)}w∈W,t∈T
Притом, матрицы Φ и Θ должны удовлетворять условиям нормировки и неот-
рицательности
X
∀d ∈ D : θdt = 1, ∀d ∈ D, ∀t ∈ T : θdt > 0 (1)
t
10Рис. 1: Графическое представление модели PLSA
X
∀t ∈ T : ϕwt = 1, ∀w ∈ W, ∀t ∈ T : ϕwt > 0 (2)
w
Строится функционал логарифма правдоподобия.
XX X
L(Θ, Φ) = ln P(D|Θ, Φ) = ndw ln ϕwt θtd → max (3)
Θ,Φ
d∈D w∈W t∈T
Таким образом, задача тематического моделирования может быть сведена к за-
даче оптимизации функционала (3) в ограничениях (2) и (1).
Такая задача может быть эффективно решена с использованием EM-алгоритма [5] [6]
(См. алгоритм 1)
3.1.2 Регуляризованный PLSA
В [7] К. В. Воронцов предложил наложить регуляризацию вида R(Θ, Φ) на функцио-
нал (3). Этот подход, в числе прочего, позволяет предопределять темы, как указывая
принадлежность слова w теме t, так и принадлежность документа d теме t. Таким
образом, от оптимизации функционала (3) в ограничениях (2) и (1) перейдем к оп-
тимизации функционала (4) в тех же ограничениях.
L(Θ, Φ) = L(Θ, Φ) + R(Θ, Φ) (4)
Обратим внимание, что регуляризация эквивалентна использованию нетриви-
ального априорного распределения на параметры Θ и Φ (возможно, несобственно-
го [8]).
Действительно,
11Алгоритм 1 EM-алгоритм для тематической модели PLSA.
Вход: набор документов D,
число тем |T |,
начальные приближения Θ и Φ
Выход: матрицы Θ и Φ;
1: повторять
2: для всех d ∈ D, w ∈ W , t ∈ T
3: nwt = 0, ndt = 0
4: для всех d ∈ D, w ∈ d
P
5: Z= ϕwt θtd
t∈T
6: для всех t ∈ T
7: δ = ndw ϕwtZθtd
8: nwt += δ, ndt += δ
9: ϕwt := nwt ∀w ∈ W ∀t ∈ T ;
10: θtd := ndt ∀d ∈ D ∀t ∈ T ;
11: отнормировать Φ и Θ в соответствии с условиями нормировки (2) и (1)
12: пока Θ и Φ не стабилизируются.
Алгоритм 2 EM-алгоритм для модели Регуляризованного PLSA.
Вход: набор документов D,
число тем |T |,
начальные приближения Θ и Φ;
Выход: матрицы Θ и Φ;
1: повторять
2: для всех d ∈ D, w ∈ W , t ∈ T
3: nwt = 0, ndt = 0
4: для всех d ∈ D, w ∈ d
P
5: Z= ϕwt θtd
t∈T
6: для всех t ∈ T
7: δ = ndw ϕwtZθtd
8: nwt += δ, ndt += δ
9: ϕwt := nwt + ϕwt ∂R(Θ,Φ)
∂ϕwt
∀w ∈ W ∀t ∈ T ;
+
10: θtd := ndt + θtd ∂R(Θ,Φ)
∂θtd
∀d ∈ D ∀t ∈ T ;
+
11: отнормировать Φ и Θ в соответствии с условиями нормировки (2) и (1)
12: пока Θ и Φ не стабилизируются.
121 R(Θ,Φ)
eL(Θ,Φ) = P(D|Θ, Φ)eR(Θ,Φ) ; P(Θ, Φ) = e
Z
Не оставим без внимания тот факт, что согласно [7] при некотором выборе
R(Θ, Φ) регуляризованный PLSA становится эквивалентен LDA [4]. Действительно,
LDA представляет собой PLSA с априорным распределением Дирихле на парамет-
рах Θ и Φ.
Обучение модели Регуляризованный PLSA можно провести, согласно [7], при
помощи алгоритма 2. Обратим внимание на тот факт, что единственное отличие
алгоритма 2 от алгоритма 1 заключается в строках 9 и 10.
3.1.3 Робастный PLSA
В 2013 году в статье [6] была предложена модификация алгоритма PLSA, нацеленная
на борьбу с тем фактом, что в документах лишь часть слов относятся к каким-
либо темам. Вводятся понятия шума и фона. Фон – набор нетематических слов,
характерный для всей коллекции, а шум - набор нетематических слов, характерных
для каждого документа.
Параметрами модели являются те же матрицы Θ и Φ, а так же
{πwd = p(w|noise, d)}d∈D,w∈W и {πw = p(w|background)}.
Очевидно, должны быть выполнены условия нормировки и неотрицательности:
X
∀d ∈ D : πwd = 1, ∀d ∈ D, ∀w ∈ W : πwd > 0 (5)
w
X
πw = 1, ∀w ∈ W : πw > 0 (6)
w
ε
Новая модель предполагает, что слово с вероятностью 1+ε+γ
генерируется из фо-
γ
на как wdi ∼ M ult(πd· ), с вероятностью 1+ε+γ
генерируется из шума как wdi ∼ M ult(π· ),
1
а с вероятностью 1+ε+γ
слово генерируется точно так же, как и в оригинальной мо-
дели PLSA.
Функционал логарифма правдоподобия тогда примет вид:
T
XX X ϕwt θtd + πw + γπdw
L(Φ, Θ, Π) = ln P(D|Θ, Φ, Π) = ndw ln → max (7)
d∈D w∈d t=1
1++γ Φ,Θ,Π
13Отдельно следует отметить невозможность одновременной оптимизации по па-
раметрам Φ, Θ, Π и ε, γ, т.к. это приводит к росту параметра γ, что соответствует
генерации всех слов из шума. Таким образом, параметры ε и γ необходимо опти-
мизировать в соответствии с некоторой внешней метрикой качества. В статье [6]
рекомендуются значения ε = 0.01 и γ = 0.3.
Согласно работе [6] для обучения модели робастного PLSA можно применять
алгоритм 3.
Алгоритм 3 EM-алгоритм для Робастной модели PLSA.
Вход: набор документов D, число тем |T |, начальные приближения Θ, Φ;
Выход: матрицы Θ, Φ и Π;
1: πdw = ndw ∀d ∈ D ∀w ∈ W
P
2: πw = ndw ∀w ∈ W
d∈D
3: Нормализовать Π в соответствии с (5) и (6)
4: повторять
5: ntd = 0; nwt = 0; nw = 0, νd = 0
6: для всех d ∈ D
P
7: Zw = ϕwt θtd + γπdw + επw ∀w ∈ d
t
8: для всех w ∈ d
9: νd += ndw γπdw /Zw
10: для всех t ∈ T
11: δ = ndw θtd ϕwt /Zw
12: ntd += δ, nwt += δ, nw += εδ
ndw Zw
13: πdw = πdw + νd − γ
+
14: ϕwt = nwt ∀w ∈ W ∀t ∈ T ;
15: θtd = ntd ∀d ∈ D ∀t ∈ T ;
16: πw = nw
17: отнормировать Φ, Θ и πw в соответствии с условиями нормировки (2), (1) и (6)
18: пока Θ, Φ и Π не стабилизируются.
143.2 Алгоритм PageRank
В 1999 году в работе [9] был описан алгоритм оценки важности интернет страниц на
основе структуры веб-графа PageRank. Таким образом, на вход алгоритму подает-
ся взвешенный ориентированный граф G = (V, E), а возвращает он ранги страниц
Rv ∀v ∈ V . Причем, веса ребер wuv отнормированы таким образом, что сумма весов
P
всех исходящих ребер равна единице: ∀u ∈ V : wuv = 1
∀v:(u,v)∈E
Вводится вектор положительных чисел Ev , характеризующих "источник ран-
га"или некоторую априорную степень предпочтения узла по причинам, не завися-
щим от графовой структуры. Зачастую полагается ∀v ∈ V : Ev = 1 Вводится также
параметр γ ∈ [0, 1].
По определению, ранг Rv вершины v равен взвешенной сумме взвешенной суммы
рангов вершин, на нее ссылающихся и вектора E
X
Rv = γ wuv Ru + (1 − γ)Ev
∀u:(u,v)
Для отыскания конкретных значений Rv в работе [9] предлагается использовать
итеративную схему (см. алгоритм 4).
Алгоритм 4 алгоритм PageRank
Вход: Граф G = (V, E),
матрица весов W = {wuv }(u,v)∈E ,
вектор положительных чисел E,
параметр γ ∈ [0, 1];
Выход: ранги Rv ;
1: положить Rv = 1 ∀v ∈ V
2: повторять
→
− →
−
3: R := γW R + (1 − γ)E
4: пока Rv не стабилизируется
Для обработки больших объемов данных сформулируем PageRank в терминах
парадигмы распределенных вычислений на графах Pregel [10] – см. алгоритм 5.
15Алгоритм 5 алгоритм PageRank в терминах Pregel
Вход: Граф G = (V, E),
матрица весов W = {wuv }(u,v)∈E ,
вектор положительных чисел E,
параметр γ ∈ [0, 1];
сообщения Mv , присланные вершине v на прошлом шаге
Выход: ранги Rv ;
1: положить Rv = 1 ∀v ∈ V
2: повторять
P
3: Rv = γ ×m.weight + (1 − γ)Ev
m∈M
4: для всех u : (v, u) ∈ E
5: SendMessage( v, wvu )
6: пока Rv не стабилизируется
3.3 Агоритм измерения глобального информационного влия-
ния TwitterRank
В статье [11] предлагается алгоритм для измерения глобального информационного
влияния TwitterRank, основанный на алгоритме PageRank и тематическом модели-
ровании.
Алгоритм принимает результаты обучения тематической модели (матрицы Θ и Φ)
и сам граф G = (V, E). Затем, для каждой темы t ∈ T он взвешивает граф по фор-
муле (8).
N
t
wvu = Pv (1 − |θvt − θut |) (8)
Ns
s:(s,u)∈E
Также определяется вектор источника ранга E t как E t = θ·t /||θ·t ||1
Затем на каждом взвешенном графе Gt = (V, E, W t ) запускается алгоритм
PageRank c вектором источника ранга E t , таким образом получая значения рангов
вершин v ∈ V по темам t ∈ T : T Rvt .
Псевдокод приведен в алгоритме 6
16Алгоритм 6 TwitterRank
Вход: Граф G = (V, E),
Сообщения пользователей {Dvi }N v
i=1 ,
Матрицы Θ и Φ,
параметр γ ∈ [0, 1];
Выход: ранги T Rvt ;
1: для всех t ∈ T
2: E t = θ·t /||θ·t ||1
t Nv
3: wvu = P
Ns
(1 − |θvt − θut |)
s:(s,u)∈E
−−→t
4: T R = P ageRank(V, E, W t , E t , γ)
3.4 Сбор подграфа социальной сети
Для обучения и оценки качества разрабатываемого алгоритма необходимо собрать
некоторый подграф социальной сети. Причем, этот подграф должен быть «репрезен-
тативным». В работе [12] предлагается формализовать «репрезентативный» подграф
как имеющая те же характеристики (показатель степени в распределении степеней
вершин, длине кратчайшего пути между парой вершин и коэффициента кластери-
зации (отношение числа ребер между соседями случайной вершины к числу всех
возможных ребер между ними)).
Также в работе [12] проводится сравнение и анализ различных алгоритмов, ре-
шающих эту задачу и делается вывод, что лучшим является алгоритм, описанный в
работе [13] и называемый Forest Fire (см. алгоритм 7).
3.5 Выводы
Согласно главе 3, на данный момент, насколько известно автору, не существует ал-
горитма, удовлетворяющего всем требованиям к поставленной задаче (см. главу 2).
Таким образом, необходимо разработать новый алгоритм, удовлетворяющий этим
требованиям.
17Алгоритм 7 Forest Fire.
Вход: начальная вершина v,
размер искомого подграфа K
Выход: подграф;
1: повторять
2: Выберем помеченную вершину c и сделаем ее непомеченной
3: если если c не подожжена то
4: Поджечь c
5: T = {v ∈ V : (v, c) ∈ E} ∪ {v ∈ V : (c, v) ∈ E}
6: если |T | 6 10000 то
7: p = 0.6
8: иначе
10000
9: p = 0.6 × |T |
10: ∀v ∈ T пометить с вероятностью p
11: пока не подожжено K вершин и есть помеченные вершины
184 Исследование и построение решения задачи
Согласно главе 3, ни один из подходов, известных на сегодняшний день, не может
быть использован для решения поставленной задачи. В связи с этим, в главе 4.1
предлагается ранее нигде не опубликованный метод оценки локального информаци-
−−→
онного влияния. Этот метод опирается на значения рангов пользователей {T Rt }t∈T
(полученных с помощью алгоритма TwitterRank – см. главу 3.3), распределения ин-
тересов пользователей {θv· }v∈V , полученные в результате алгоритма тематического
моделирования, описанного в главе 4.3, графовую близость (алгоритмы нахождения
графовой близости описаны в главе 4.5), а также на структуру сообществ пользова-
телей в социальном графе (см. главу 4.6).
В главе 4.2 описывается возможность улучшения предложенного метода посред-
ством применения методов машинного обучения с учителем.
Поскольку используемый алгоритм тематического моделирования относится к
разряду алгоритмов частичного обучения с учителем [14], ему необходимы размечен-
ные данные для обучения. Процесс получения необходимых данных описан в главе
4.7
В главе 4.8 описаны методы, примененные для оценки качества тематической
модели и разработанного алгоритма оценки социального влияния.
4.1 Оценка локального влияния
Ниже излагается нигде ранее не опубликованный способ оценки локального инфор-
мационного влияния влияние Ivu агента u на реципиента v.
t
Обозначим степень влияния пользователя v на пользователя u по теме t как Ivu ,
S
влияния пользователя v на пользователя u по множеству тем S ⊂ T как Ivu и то-
T
гда Ivu = Ivu
t
Во-первых, сделаем важное допущение. Локальное влияние Ivu отлично от нуля, ко-
гда пользователи v и u находятся в одном сообществе, т.е.
S
(6 ∃C ∈ C : v ∈ C&u ∈ C) ⇒ ∀S ⊂ T → Ivu =0 (9)
t
Если пользователи v и u лежат в одном сообществе, определим значение Ivu как
t
Ivu = θtv T Rtu sim(v, u) (10)
19Здесь sim(v, u) обозначает, вообще говоря, несимметричное расстояние от агента
u до реципиента v.
t
Согласно формуле (10), Ivu тем больше, чем чем больше интерес реципиента v
в теме t, чем больше глобальная степень влияния агента u и чем агент v ближе к
реципиенту u в смысле графа. Это вполне согласуется с интуитивным пониманием
t
величины Ivu .
S
Будем искать величину Ivu как
X
S t
Ivu = Ivu (11)
t∈S
4.2 Подход с использованием машинного обучения с учителем
для оценки локального влияния
Индикатором влияния может также считаться факт ретвита (см. главу 4.8) одного
пользователя другим [15].
Предлагается использовать следующие признаки:
1. Значение графовой близости между реципиентом и агентом
2. Вектор интересов реципиента θv·
3. Вектор рангов агнета T Ru·
Данная задача может быть рассмотрена как задача регрессии: в качестве откли-
ка примем сколько раз реципиент v ретвитил агента u, и как задача классификации:
в качестве отклика примем, ретивтил ли реципиент v агента u.
Имея обученный классификатор (или регрессионную модель) a(·, ·, ·), можно
определить влияние следующим образом
T
Ivu = a(sim(v, u), θv· , T Ru· ) (12)
В качестве алгоритма классификации и регрессии в данной работе используется
алгоритм RandomForest, предложенный в [16].
Данный алгоритм был выбран всилу его хорошей масштабируемости и паралле-
лезуемости, а так же его способности вернуть не только значение отклика, но и его
распределение.
20Такой подход, однако, обладает существенным недостатком. Автору совершенно
неочевидны пути обобщения данного подхода на оценку влияния по произвольному
подмножеству тем S ⊂ T , поскольку неизвестно, по какой именно теме произошел
ретвит, а тематическое моделирование на уровне одного короткого сообщения соци-
альной сети Twitter сопряжено с определенными трудностями [17].
4.3 Выбранная тематическая модель
В соответствии с предъявленными требованиями будем использовать робастный ре-
гуляризованный PLSA, при этом, выберем функцию R(Θ, Φ) следующим образом.
R(Θ, Φ) = τac Rac (Φ) + τs−s Rs−s (Θ); τac , τs−s < 0 (13)
где
X X
Rac (Φ) = Cov(ϕt· , ϕs· ) (14)
t∈T s∈T \s
Применение регуляризатора Rac – формализация нашего требования получить
различные, а значит, более интерпретируемые темы.
Регуляризатор Rs−s формализует априорное знание о принадлежности некото-
рых документов темам. Пусть у нас есть множество пар вида
P = {(d, t) : d ∈ D, t ∈ T }, формализующих принадлежность некоторых документов
нашей коллекции D темам. Тогда функционал Rs−s принимает вид:
XX
Rs−s (Θ) = [(d, t) ∈ P ] ln θtd (15)
t∈T d∈D
Для описания алгоритма оптимизации функционала (4) с функционалом L(Θ, Φ)
вида (7), регуляризатором R(Θ, Φ) вида (13)(14)(15) в ограничениях (6), (5), (2) и (1)
нам потребуется найти градиент функционалов (14) и (15).
∂Rac (Φ) X
= ϕws (16)
∂ϕwt
s∈T \s
∂Rs−s (Θ) 1
= [(d, t) ∈ P ] (17)
∂θdt θtd
21Для обучения такой модели предлагается использовать алгоритм 8, полученный
из алгоритма 3 модификацией строк 14 и 15 в соответствии с алгоритмом 2 и видом
нашего регуляризатора (13).
Алгоритм 8 EM-алгоритм для Робастной модели PLSA.
Вход: набор документов D, число тем |T |, начальные приближения Θ, Φ;
Выход: матрицы Θ, Φ и Π;
1: πdw = ndw ∀d ∈ D ∀w ∈ W
P
2: πw = ndw ∀w ∈ W
d∈D
3: Нормализовать Π в соответствии с (5) и (6)
4: повторять
5: ntd = 0; nwt = 0; nw = 0
6: для всех d ∈ D
P
7: Zw = ϕwt θtd + γπdw + επw ∀w ∈ d
Pt
8: νd = ndw γπdw /Zw
w∈d
9: для всех w ∈ d
10: для всех t ∈ T
11: δ = ndw θtd ϕwt /Zw
12: ntd += δ, nwt += δ, nw += εδ
13: πdw = πdw + nνdw d
− Zw
γ
+
14: ϕwt := nwt + ϕwt ∂R∂ϕacwt(Φ) ∀w ∈ W ∀t ∈ T ;
+
15: θtd := ndt + θtd ∂R∂θ
s−s (Θ)
td
∀d ∈ D ∀t ∈ T ;
+
16: πw = nw
17: отнормировать Φ, Θ и πw в соответствии с условиями нормировки (2), (1) и (6)
18: пока Θ, Φ и Π не стабилизируются.
4.4 Методы ускорения обучения тематической модели
В данном разделе описываются два метода ускорения обучения модели PLSA. Оба
метода обобщаются на робастный и/или регуляризованный PLSA. Описываемые в
данном разделе методы были разработаны в ходе работы над данным дипломом. В
главе 4.4.1 описан метод, основанный на факте, что для извлечения тем из боль-
шой коллекции документов достаточно рассмотреть лишь некоторое подмножество.
Метод, описанный в главе 4.4.2, предлагает искать начальное приближение для ал-
22горитма обучения PLSA неслучайным образом, благодаря чему алгоритм сходится
за меньшее число итераций.
4.4.1 Метод получения тем по подмножеству обучающей выборки
Описываемый метод основан на том факте, что для извлечения тем из большой
коллекции документов достаточно рассмотреть лишь некоторое подмножество (ре-
презентативное подмножество).
Т.е. предлагается сгенерировать подмножество обучающей выборки (согласно [1]
в разы меньшего размера, чем вся выборка при большом объеме всей выборки).
На подмножестве обучить алгоритм PLSA, получив тем самым, матрицу Φ̂. Далее
предлагается для каждого документа из обучающей выборки определить стобец θd·
посредством оптимизации функционала (18) в ограничениях (1).
X X
L(θ·d ) = ndw ln ϕ̂wt θtd → max (18)
θ·d
w∈W t∈T
Согласно работе [1], данный метод не приводит к существенному снижению каче-
ства (как по значению функционала праводоподобия, так и по прикладным задачам
классификации). Следует отметить, что данный метод применим исключительно к
большим коллекциям документов. Большими коллекциями документов будем назы-
вать те, в которых репрезентативное подмножество меньше всей выборки в несколько
раз.
Нельзя оставить без внимания тот факт, что в силу независимости вычислений
столбцов θ·d распределенная версия описываемого метода тривиальна и чрезвычайно
эффективна (главным образом, благодаря нулевой коммуникации).
Согласно экспериментам, описанным в работе [1], описанный подход позволяет
получить 5-13и–кратное ускорение.
4.4.2 Метод, основанный на поиске неслучайного начального приближе-
ния, позволяющего сократить число итераций алгоритма обучения
PLSA
Предлагаемый метод изложен в алгоритме 9.
23Идея описываемого подхода заключается в том, что документы приближаются
выпуклой комбинацией тем, поскольку задача тематического моделирования есть
задача декомпозиции в смысле Кульбака-Ляйблера [18]. Действительно,
XX X
L(Θ, Φ) = ln P(D|Θ, Φ) = ndw ln ϕwt θtd = KL(D, ΘΦ) + const (19)
d∈D w∈W t∈T
X XX aij
KL(A, B) = KL(ai· , bi· ) = aij ln (20)
i i j
bij
Алгоритм 9 Алгоритм ускоренного обучения PLSA, основанный на поиске неслу-
чайного начального приближения
Вход: набор документов D,
число тем |T |,
сглаживающий параметр ε > 0,
Выход: матрицы Θ, Φ;
1: Выбрать случайно S ∈ D : |S| ≈ |D|/10
2: Получить Φ0 , ΘS , обучив PLSA на S со случайными начальными приближениями
3: Определим пространство, натянутое на столбцы матрицы Φ : H = hϕ1· , ϕ2· , ...ϕT · i
4: Теперь ортогонально проецируем документы всей коллекции nd· на пространство
H. Получаем вектора ηd·
5: Заменяем отрицательные ηd· нулями
6: ηdw = ηdw + ε
0
7: θdt = ηdt /||ηd· ||1
8: Обучаем PLSA на всей коллекции с начальными приближениями Θ0 и Φ0
Как показано в статье [1], данный алгоритм позволяет в 1.5 раза сократить число
итераций алгоритма обучения PLSA без какой-либо потери качества (как в значении
функционала, так и на прикладных задачах классификации).
4.5 Алгоритмы определения графовой близости пары вершин
Согласно определению локального влияния, степень влияния тем больше, чем «бли-
же» находится агент к реципиенту. Таким образом, остро встает проблема расчета
величины sim(v, u) – «близости» между парой вершин в смысле графа.
244.5.1 Алгоритмы нахождения максимального потока
Наиболее разумным выглядит определить «близость», в таком случае, как макси-
мальный поток. Однако, главным требованием к системе является масштабируе-
мость. На сегодняшний день самый быстрый (1 − )-приближенный алгоритм поиска
максимального потока между парой вершин, описанный в работе 2014-го года [19],
имеет сложность O(|E|1+o(1) −2 ) и он не пригоден к работе с ориентированными гра-
фами.
В работе [20] предлагается свести проблему максимального потока в направлен-
ном графе к аналогичной проблеме в ненаправленном c линейной вычислительной
сложностью и размером нового графа, превышающим размер старого в константу
раз.
Однако, нам необходимо уметь решать такую проблему для всех пар вершин.
Использование такого подхода приведет к квадратичной сложности, что неприемле-
мо для заданных объемов данных.
4.5.2 Алгоритмы нахождения длины кратчайшего пути
По причинам, изложенным в предыдущей подглаве, было решено считать «близость»
как величину, обратную длине кратчайшего пути.
sim(u, v) = K(d(u, v)) (21)
Здесь K - некоторая монотонно убывающая положительная функция, причем
lim K(x) = 0, таким образом, K(d(v, u)) выражает «близость» в смысле графа.
x→∞
С детерминированными алгоритмами поиска расстояния между всеми парами
вершин ситуация не лучше – в любом случае, если мы планируем рассчитать все
расстояния заранее, мы будем иметь квадратичную сложность (по времени вывода
результата), таким образом, нам необходимо обратиться к методам, способным за
время, близкое к линейному, рассчитать какие-то значения, из которых далее мы
очень быстро сможем получать расстояние между парой вершин по запросу.
Вмещение графов.
Один из таких подходов называется вмещение графа (graph embedding). Со-
гласно [21], подход заключается в том, чтобы отобразить вершины V в некоторое
25метрическое пространство (Σ, d(·, ·)) таким образом, чтобы расстояние между обра-
зами вершин в этом пространстве было близко к расстоянию между ними в графе.
Работа [22] предлагает распределенное решение такой задачи за линейное по
числу ребер время.
Суть алгоритма в следующем. Пусть зафиксировано малое подмножество вер-
шин L ⊂ V . От них мы можем найти расстояния до всех вершин с помощью алгорит-
ма Дейкстры [23] (имеющего сложность O(|E| + |V | log |V |)). Далее мы определяем
координаты xv вершин v ∈ L из оптимизации следующего функционала
XX
L({xv }v∈L ) = d(xv , xu ) → min (22)
{xv }v∈L
v∈L u∈L
Далее координата всех остальных вершин u ∈ V \ L находится независимо из
оптимизации функционала
X
L(xu ) = d(xu , xv ) → min (23)
xu
v∈L
К сожалению, такой подход обладает существенным недостатком: он не при-
менялся авторами статьи для для направленных графов. Разумеется, можно рас-
смотреть вмещение в пространство с несимметричной метрикой [24], однако, автору
данной дипломной работы неизвестно о практическом применении подобного подхо-
да.
Подход на основе ориентиров.
В работе [25] предлагается подход оценки длины минимального пути в графе
между парой вершин на основе ориентиров (landmarks).
Предлагается выбрать подмножество вершин L ⊂ V , называемых ориентирами.
Далее, от каждой вершины l ∈ L находятся расстояния до всех остальных вершин в
графе d(l, v) ∀v ∈ V .
Теперь расстояние между произвольной парой вершин u, v ∈ V можно оценить
с помощью неравенства треугольника
d(u, v) > sim(v, u) = max d(l, v) − d(l, u) = sim (24)
l∈L
Как утверждают авторы [25], достаточно взять O(log |V |).
26Поиск расстояний от ориентиров имеет сложность O(|L|(|V | log |V | + |E|)), ответ
же на запрос о расстоянии между парой вершин может быть получен за O(|L|) =
O(log |V |) операций.
4.5.3 Близость на основе сообществ
На основе графа G = (V, E) мы можем извлечь сообщества вершин C = {Ci }N
i=1 : Ci ⊂ V
c
(см. главу 4.6).
Две вершины тем «ближе», чем в большем числе сообществ они состоят вме-
сте. Будем считать близость как коэффициент Жаккарда [26] между множествами
сообществ, в которые входят вершины:
sim(v, u) = J({i|v ∈ Ci }, {i|u ∈ Ci }) (25)
где
|A ∩ B|
J(A, B) = (26)
|A ∪ B|
4.6 Алгоритм поиска сообществ пользователей
Согласно работе [27], пользователи социальных сетей склонны объединяться в сооб-
щества, устанавливая связи на основе общей или близкой деятельности, социального
статуса, круга или других свойств.
Алгоритм поиска сообществ принимает на вход взвешенный граф G = (V, E, W )
и выдает семейство множеств C = {Ci }N
i=1 : Ci ⊂ V . Обратим внимание, что число
c
извлекаемых сообществ не является параметром алгоритма.
4.6.1 Алгоритм SLPA
В качестве простого алгоритма поиска сообществ, допускающего тривиальную рас-
пределенную реализацию, рассмотрим SLPA, описанный в работе [28].
Изложим суть алгоритма.
Каждой вершине v ∈ V приписывается некоторая «память» mv . Частотой эле-
|{y|y∈mv &y=x}|
мента x в памяти будем называть величину, равную |mv |
. Во время иници-
ализации каждая вершина добавляет в «память» свой номер: mv = {v}. На каждой
27итерации каждая вершина v посылает каждому своему соседу u : (v, u) ∈ E равнове-
роятно выбранный элемент множества mv . Затем, дождавшись прихода всех сообще-
ний mr от своих соседей f : (f, v) ∈ E, выбирает самый частый элемент из множества
mr (в случае, если максимум частоты достигается у нескольких элементов, из них
равновероятно выбирается один) и добавляет его в свою «память». Повторять до
сходимости частот элементов в «памятях» (согласно [28], сходимость достигается по-
сле 20ти итераций). Далее, каждая вершина удаляет из своей "памяти"элементы,
встречающиеся в ней реже чем p(N + 1) раз, где N -число итераций, а p -параметр
алгоритма. Теперь элементы «памятей» будем считать индексами сообществ, в кото-
рые вершина включена. Теперь вернем семейство
C = {C|∃x ∈ V : C = Cx = {v ∈ V |x ∈ mv }&Cx 6= ∅}, которое может быть получено
тривиальной группировкой.
К преимуществам этого алгоритма следует отнести низкую вычислительную
сложность, способность работать на взвешенных и ориентированных графах и три-
виальную выразимость терминах парадигмы распределенных вычислений на графах
Pregel [10] – см. алгоритм 5.
4.6.2 Применение алгоритма SLPA
В данной работе для поиска сообществ предлагается использовать алгоритм SLPA
(см. главу 4.6.1) на взвешенном графе G = (V, E, W ), где веса рассчитаны по извест-
ному распределению интересов θv· пользователя v, полученных в результате темати-
ческого моделирования сообщений пользователя.
wuv = JS(θu· , θv· ), ∀(u, v) ∈ E (27)
Здесь JS(·, ·) – дивергенция Йенсена-Шеннона [18], являющаяся метрикой в про-
странстве распределений и определяемая как
1
JS(p, q) = (KL(p, q) + KL(q, p)) (28)
2
Где KL(·, ·) – дивергенция Кульбака-Лейблера [18], определяемая как
Z
p(x)
KL(p, q) = p(x) ln dx (29)
q(x)
284.7 Сбор размеченных документов
Одним из требований к разрабатываемому алгоритму является способность рабо-
тать с предопределенными (в некоторой степени) темами. Согласно [7] есть два
основных способа задания предопределенных тем. Можно задать множество пар
{(w, t) : w ∈ W, t ∈ T }, указывая на принадлежность терминов темам, либо можно
задать множество пар {(d, t) : d ∈ D, t ∈ T }, указывая на принадлежность докумен-
тов темам.
Мы остановимся на последнем варианте, поскольку первый подразумевает рабо-
ту живого человека, способного соотнести темам термины. Разумеется, задача соот-
несения документов темам может быть решена человеком, мы нашли способ обойтись
без этого.
DMOZ.
DMOZ2 , согласно [29], является хорошим источником группированных по те-
мам документов. Согласно [30] DMOZ распределяет всевозможные сайты согласно
обширной иерархии категорий силами 52000 добровольцев.
Хештэг.
Согласно работе [31], хэштегом называется часть сообщения (слово, начинаю-
щееся со знака «#»). Пользователи социальной сети используют хэштеги как способ
категоризации сообщения и подчеркивания его темы. Также социальная сеть позво-
ляет легко запрашивать сообщения, содержащие конкретный хэштег.
Алгоритм сбора сообщений с известными темами.
Суть предлагаемого алгоритма заключается в том, что названия подкатегорий
категории, равно как и название категории, могут быть хэштегом в сообщении, от-
носящимся к этой категории.
Потому предлагается взять все категории второго уровня иерархии c (напр.
«Фильмы») и для каждой определить множество ключевых слов Kc , в которое входят
названия всех ее подкатегорий третьего уровня иерархии (напр., «Актеры и Актри-
сы») и ее собственное название. Далее предлагается удалить из множеств ключевых
S
слов все слова, встречающиеся более чем в одном множестве: Kc := Kc \ ( Ks ).
s6=c
Наконец, запрашиваем в социальной сети сообщения, содержащей хештеги из Kc ,
получая таким образом сообщения, относящиеся к категории c.
2
http://www.dmoz.org/
294.8 Методы оценки качества
4.8.1 Оценка качества работы тематической модели
В работах [32] [33] [34] [35] описывается множество способов автоматической оценки
интерпретируемости тем и проводится их сравнение с суждениями экспертов.
Предлагается использовать метод PMI (pointwise mutual information). К досто-
инствам этого метода следует отнести:
1. Полная автоматизированность и независимость от внешних ресурсов (напри-
мер, поисковой системы)
2. Способность работать с любыми типами текстов (язык социальных сетей не
является литературным)
3. Высокая степень согласованности с экспертами (значение ранговой корреляции
Спирмэна [36] до 0.77 )
Для примененения метода PMI необходимо оценить по некоторому набору доку-
ментов следующие параметры: p(w1 , w2 ) ∀w1 , w2 ∈ W – вероятность встретить пару
слов w1 и w2 в документе на расстоянии менее 10ти слов и p(w) ∀w ∈ W – вероят-
ность слова w.
Далее для оценки интепретируемости темы t предлагается найти 10 слов Wttop с
самыми большим значениями θwt . В качестве меры интерпретируемости темы пред-
лагается принять
X X p(w1 , w2 )
P M I(w1 , w2 ) = log2 (30)
p(w1 )p(w2 )
w1 ,w2 ∈Wttop w1 ,w2 ∈Wttop
4.8.2 Оценка качества оценки информационного влияния пользователей
В работе [2] предлагается оценивать качество оценки информационного влияния
пользователей, используя информацию о ретвитах. В социальной сети Twitter3 поль-
зователь, увидев понравившееся ему сообщение другого пользователя, может пере-
писать его (с указанием исходного авторства) в свой микроблог. В таком случае го-
3
http://www.twitter.com
30ворят, что один пользователь ретвитил другого, а само такое сообщение называют
ретвитом.
Для оценки качества подходов, описанных в главах 4.1 и 4.2 предлагается по-
строить линейный классификатор вида [Ivu > C] для предсказания ретвитов поль-
зователя u от пользователя v. Введем предикат R(v, u), истинный тогда и только
тогда, когда пользователь u когда-либо ретвитил пользователя v. Теперь будем счи-
тать, что классификатор принял правильное решение тогда и только тогда, когда
(Ivu > C) = R(v, u)
Единственное отличие в оценке качества подходов из глав 4.1 и 4.2 заключает-
ся в том, что при оценке подхода из главы 4.2 необходимо избежать тестирования
на тех парах реципиент-агент, что были использованы для обучения. Предлагается
использовать скользящий контроль (cross-validation) [37].
Для оценки качества такого классификатора предлагается использовать меру
AUC, усредненную по всем пользователям.
4.8.3 Площать под ROC-кривой
Площать под ROC-кривой (AUC), согласно [37], является одной из основных харак-
теристик бинарного классификатора вида a(x) = [f (x) > C].
Для определения AUC введем некоторые базовые определения. Пусть тестирова-
ние классификатора a(x) производится на множестве объектов c ответами {(xi , yi )}li=1 .
Базовые обозначения даны в таблице 1.
yi = 1 yi = 0
a(xi ) = 1 tp fp
a(xi ) = 0 fn tn
Таблица 1: Базовые обозначения
Пусть также p = |{i|yi = 1}| и n = |{i|yi = 0}|
tp tn
Теперь можно определить tpr = p
и tnr = n
.
ROC-кривая определяется как множество точек {(tpr(C), tnr(C))|C ∈ R}.
Соответственно, AUC, как площадь под ней, может быть найдена как
Z
AU C = tpr(C) dtnr(C) (31)
C
314.9 Выводы
В этой главе был представлен новый алгоритм оценки социального влияния на ос-
нове тематического моделирования, алгоритма TwitterRank и графовой близости,
удовлетворяющий всем требованиям, описанным в главе 2.
В главе 5 описывается реализация этого алгоритма и использованный при этом
инструментарий.
325 Описание практической части
5.1 Выбранный инструментарий
Для реализации распределенной системы был выбран Map-Reduce [38] фреймворк
Apache Spark [39] [40]. Парадигма Map-Reduce была выбрана ради удобства реали-
зации, устойчивости к отказам и горизонтальной масштабируемости. Выбор Spark
обусловлен его высокой производительностью (до 100 раз более высокой, чем у дру-
гого распространенного фреймворка Hadoop [41]), богатым набором примитивов и
наличием реализации парадигмы распределенной обработки графов Pregel [10] –
Bagel [42].
Фреймворк Apache Spark написан на языке программирования Scala [43], его ос-
новной API также сделан максимально удобным для вызова именно из этого языка
программирования. К достоинствам языка Scala следует также отнести простую ин-
теграцию с системами, написанными на языке Java, что позволяет использовать все
многообразие библиотек, написанных на Java.
В качестве реализации алгоритма машинного обучения RandomForest [16] и ин-
струментов анализа ROC-кривых [37] был использован Matlab [44].
Для хранения промежуточных данных было решено использовать key-value хра-
нилище Redis [45]. Redis хранит все данные в оперативной памяти, что позволяет
особенно быстро обрабатывать запросы. Очевидным недостатком является то, что
все данные должны помещаться в оперативную память.
5.2 Общая схема работы
Работа системы разбивается на два шага
1. предобработка графа и получение всех необходимых промежуточных данных
(см. алгоритм 10)
2. обработка запросов на оценку влияния на заданного пользователя со стороны
других пользователей (см. алгоритм 11)
Обращаем внимание, что каждый шаг алгоритма 10, сложность которого за-
висит от размеров графа G, допускает распределенную реализацию, а алгоритм 11
имеет вычислительную сложность, не зависящую от размеров графа G.
33Алгоритм 10 Общая схема предобработки
Вход: Граф G = (V, E),
Сообщения пользователей {Dvi }N v
i=1 ,
Количество тем |T |,
Количество ориентиров |L|,
Выход: сохраненные в Redis отображения:
распределения интересов пользователей v → θv· ,
пользователи, входящие в одно сообщество с заданным v → {Ci }i:v∈Ci ,
значения рангов пользователей v → T Rv ,
расстояния от ориентиров до остальных вершин v → dv·
1: Dv = concat({Dvi }N
v∈V )∀v ∈ V
v
2: (Θ, Φ) = topicM odel({Dv }v∈V )
3: сохранить в Redis отображение v → θv·
4: рассчитать Wc по формуле (27)
5: отыскать сообщества C = {Ci }N
i=1 с помощью SLPA в графе Gc = (V, E, Wc )
c
6: сохранить в Redis отображение v → {Ci }i:v∈Ci
7: выбрать множество ориентиров L ∈ V и найти расстояния dlv от них до остальных
вершин v ∈ V в графе G = (V, E, Wc )
8: сохранить в Redis отображение v → dv·
9: для всех t ∈ T
10: рассчитать Wr в соответствии с (8)
11: отыскать значения T Rv c помощью алгоритма TwitterRank на графе
Gr = (V, E, Wr )
12: сохранить значения T Rv в Redis как v → T Rv
13: обучить классификатор на данных {(sim(v, u), θv· , T Ru· ), R(u, v)}v,u∈V &∃i:v,u∈Ci
34Алгоритм 11 Общая схема ответа на запрос
Вход: сохраненные в Redis отображения:
распределения интересов пользователей v → θv· ,
пользователи, входящие в одно сообщество с заданным v → {Ci }i:v∈Ci ,
значения рангов пользователей v → T Rv ,
расстояния от ориентиров до остальных вершин v → dv· ,
пользователь u,
темы, влияние по которым необходимо оценить S ⊂ T
Выход: список локальных агентов влияния с оценками степени их влия-
ния {(v, Ivu )|v ∈ V, Ivu > 0}
1: запросить у Redis C = {Ci }i:u∈Ci
S
2: для всех v ∈ C
3: запросить у Redis dlv ∀l ∈ L
4: в зависимости от выбранного способа рассчета близости, рассчитать sim(v, u)
по формуле (25) или (24)
5: запросить у Redis значение T Rv
6: запросить у Redis значение θu
7: рассчитать Ivu по формуле (11) или (12)
355.3 Выводы
В этой главе была описана схема работы алгоритма, его реализация и использован-
ный инструментарий.
В главе 6 описывается эксперименты по оценке качества разработанного алго-
ритма, а также производительность и масштабируемость его распределенной реали-
зации.
366 Эксперимент
Поскольку нами используется алгоритмы машинного обучения, нам необходимы дан-
ные для обучения. Использованные в экспериментах наборы данных описаны в главе
6.1.
В главе 6.2 описан подбор оптимальных параметров для тематической модели и
значения достигнутой меры интерпретируемости PMI.
Глава 6.3 описывает результаты оценки качества разработанного алгоритма по
методике, описанной в главе 4.8.2.
Результаты тестирования производительности и масштабируемости реализации
алгоритма приведены в главе 6.4
6.1 Описание данных
Для оценки качества были использованы реальные данные, скачанные из сети
Twitter4 с помощью Twitter REST API 5 . Параметры этого датасета представлены в
таблице 2
Количество пользователей, |V | 11049
P
Общее количество сообщений, Nv 12151483
v∈V
1
P
Среднее количество сообщений пользователя, |V |
Nv 1099
v∈V
Дата самого раннего сообщения 2006-03-21
Дата самого позднего сообщения 2013-06-17
Таблица 2: Параметры датасета, скачанного из Twitter
Для оценки масштабируемости и производительности использовались синтети-
ческие датасеты [46].
6.2 Экспериментальная оценка качества тематической модели
Для определения качества модели, поскольку основным критерием является ее ин-
терпретируемость, предлагается использовать меру PMI (см. главу 4.8.1).
4
http://www.twitter.com
5
https://dev.twitter.com/docs/api
37Также необходимо определить оптимальные значения параметров τs−s и τac (см.
главу 4.3). Это было сделано перебором параметров по экспоненциальной сетке, на-
чиная с 1 с показателем 10.
Итого было получено медианное значение PMI по всем темам 1.61 (95% довери-
тельный интервал: [1.48, 1.74]), что превышает значения, достигнутые в работе [47].
6.3 Экспериментальная оценка качества предсказания локаль-
ных агентов влияния
Были проведены эксперименты, оценивающие качество предсказания локальных
агентов влияния по способности предсказания ретвита (см. главу 4.8.2) с различ-
ными способами оценки расстояния между пользователями sim(v, u) (см. главу 4.5).
Результаты приведены в таблице 3.
Способ оценки sim(v, u) AUC гл. 4.1 AUC гл. 4.2
Точная длина минимального пути 0.61 0.68
Оценка длины минимального пути на основе ориентиров 0.64 0.70
Оценка на основе сообществ 0.64 0.70
Таблица 3: Качество качество предсказания локальных агентов влияния в зависимо-
сти от способа оценки sim(v, u)
Оценка длины минимального пути на основе ориентиров производилась с экспе-
риментально определенным значением |L| = 50.
Таким образом, мы видим отсутствие преимущества у подхода на основе ориен-
тиров перед подходом на основе сообществ. Причем, подход на основе сообществ не
требует от нас дополнительных вычислений (сообщества нам в любом случае нуж-
ны). Таким образом, подход на основе сообществ следует признать предпочтитель-
ным.
95% доверительный интервал для значения AUC для метода, описанного в главе
4.2 c оценкой графовой близости на основе сообществ: [0.690, 0.712].
Притом, как и следовало ожидать, подход, описанный в главе 4.2 работает зна-
чительно лучше подхода, описанного в главе 4.1. Отметим, что результат, получен-
ный с применением подхода, описанного в главе 4.2, ненамного уступает подходу,
описанному в статье 4.8.2 (авторы заявляют о AUC на уровне 0.71-0.72).
386.4 Оценка производительности
Для оценки производительности предобработки, запустим нашу распределенную си-
стему на кластере из 6-ти вычислителей и 1-го главного узла с 32 процессорами и
60Гб оперативной памяти на каждой машине.
На вход системе будем подавать синтетические данные различных размеров.
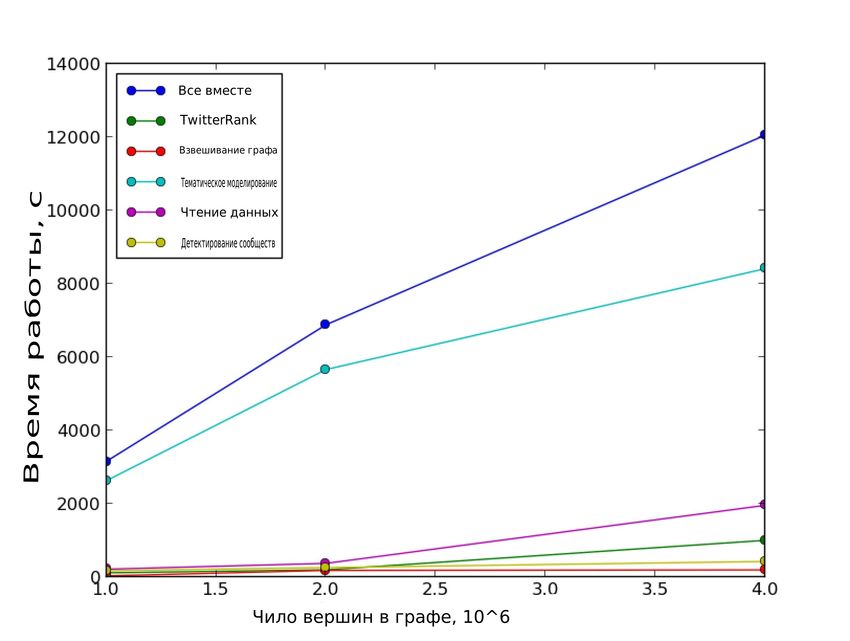
Результаты изображены на рисунке 2. По результатам видно, что наша система дей-
ствительно имеет линейную или близкую к линейной вычислительную сложность.
Рис. 2: Зависимость времени работы от объема данных
Для оценки времени обработки запроса после предобработки синтетических гра-
фов различных размеров запустим выполнение большого числа случайных запросов.
Результаты приведены на рисунке 3. По результатам видно, что время обработки за-
проса действительно не увеличивается с ростом объема данных.
39Рис. 3: Зависимость времени обработки запроса от объема данных
6.5 Оценка масштабируемости
Также необходимо оценить масштабируемость системы. Для этого произведем за-
мер времени работы на случайно сгенерированном графе размера |V | = 5 × 105 в
зависимости от числа машин, включенных в кластер.
Будем использовать машины с 4-мя процессорами и 6.4Гб оперативной памяти
на каждой.
График зависимости скорости работы от числа машин приведен на рисунке 4.
По нему можно видеть, что система демонстрирует масштабируемость, близкую к
линейной.
40Рис. 4: Зависимость скорости работы от числа машин в кластере
6.6 Выводы
Экспериментально были подобраны оптимальные параметры тематической модели.
Как показал эксперимент, наибольшее качество работы алгоритма оценки социаль-
ного влияния (AU C = 0.70 ± 0.01) достигается при использовании в качестве меры
графовой близости меру, основанную на сообществах (см. главу 4.5.3), что оказыва-
ется на уровне результатов, объявленных в статье [2].
Как показал эксперимент, алгоритм обучения разработанного алгоритма име-
ет временную сложность, близкую к линейной, что согласуется с теоретическими
оценками, а время работы обученного алгоритма не зависит от размеров графа, что
так же согласуется с теоретическими оценками. Также продемонстрирована близ-
41Вы также можете почитать

















































