ДНК-микрочипы и анализ данных по экспрессии генов
←
→
Транскрипция содержимого страницы
Если ваш браузер не отображает страницу правильно, пожалуйста, читайте содержимое страницы ниже
ДНК-микрочипы и анализ данных по экспрессии генов
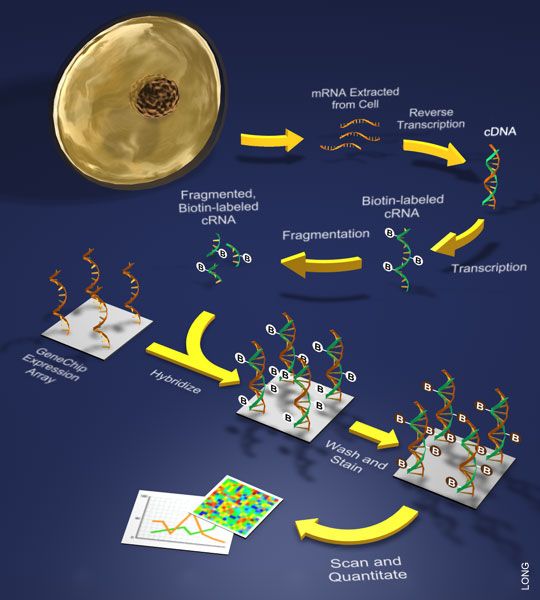
ДНК-микрочипы • Способ измерения уровня экспрессии РНК для каждого гена. • Принцип действия: гибридизация мРНК с зондом - комплиментарной ДНК последовательностью закрепленной на твердой поверхности (чипе).
ДНК-микрочипы
ДНК-микрочипы
Обратная Гибридазация Измерения
транскрипция
ДНК 1
ДНК 2
Ген 1
Ген 2
РНК 4 кДНК4
ДНК 3
ДНК 4
Ген 3
Ген 4
ДНК 5
ДНК 6
Ген 5
Ген 6
РНК 6 кДНК 6
ДНК-микрочипы
• Двумерный массив ДНК-зондов для тысяч
нуклеотидных последовательностей.
• Каждая ячейка содержит несколько копий
определенной последовательности ДНК.
• Возможность оценки числа гибридизаций
для каждой ячейки.
• Один микрочип по сути позволяет
одновременное выполнение тысяч
экспериментов - по одному для каждого
гена.
• Измерение экспрессии генов при разных
условиях
Матрица данных по экспрессии
Условие 1
Условие 2
N экспериментов (условий)
Сравнение схожести профилей экспрессии
профиль экспрессии гена
M генов
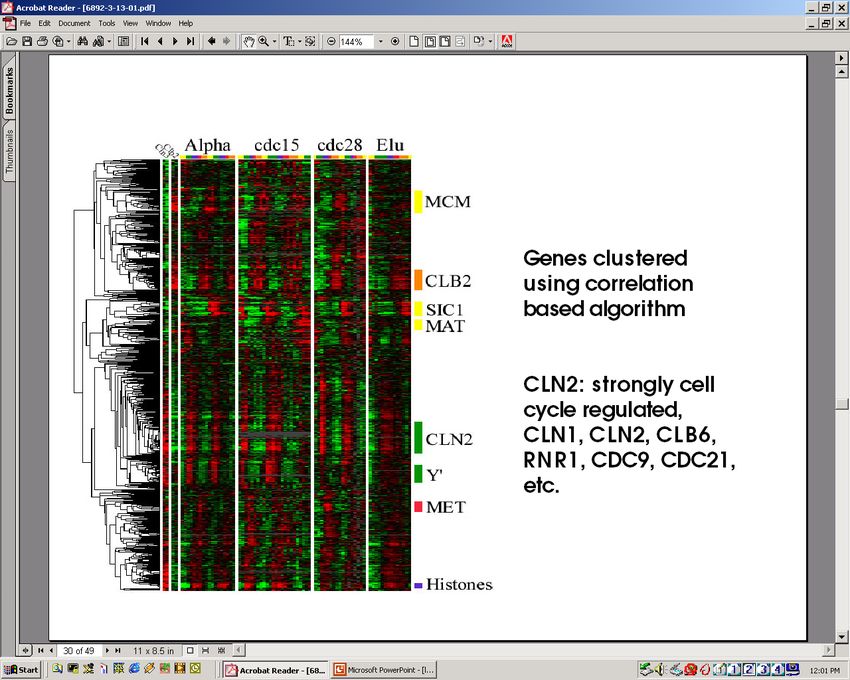
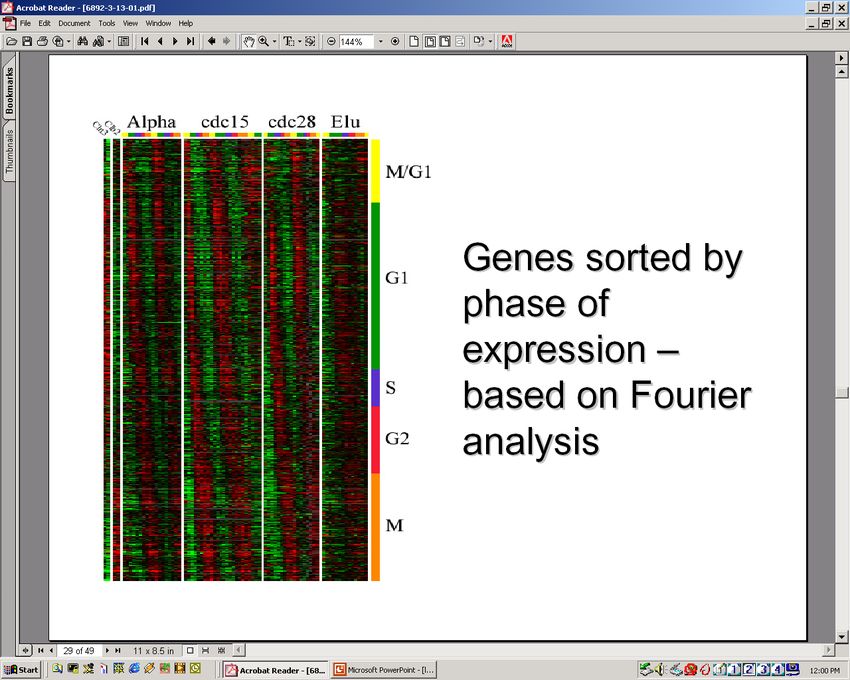
Сравнение схожести условийПрименение методов кластеризации и классификации
для анализа данных по экспрессии генов
• Кластеризация
Утверждение: Группы генов выполняющие схожие функции имеют схожие профили
экспрессии.
Задача: Поиск функциональных групп генов.
Методы:
- Иерархическая кластеризация
- Метод k-средних
- др.
• Классификация
Утверждение: Клетка может находится в разных состояних (здоровая/раковая),
различающихся уровнями экспрессии генов.
Задача: Определения состояния клетки на основе данных о профилях экспрессии генов.
Методы:
- Наивный Байесовский классификатор
- Деревья решений
- Нейронные сети
- Метод опорных векторовКластеризация и классификация
• Объекты характеризуются одним или
Признак 2
несколькими признаками
• Классификация
- Для некоторых объектов известны их
метки.
- Задача найти правило, позволяющее
присвоить метки остальным объектам.
- Обучение с учителем (supervise learning). Признак 1
• Кластеризация
- Метки объектов неизвестны.
Признак 2
- Задача объединить объекты в группы
(кластеры), на основании их схожести
(расстояния между объектами).
- Обучение без учителя (unsupervise
learning).
Признак 1Алгоритмы кластеризации • Разделяющие Делят все объекты на непересекающиеся множества (кластеры), при этом каждый объект принадлежит только одному кластеру. • Объединяющие Итеративно объединяют объекты в кластеры, и далее сами кластеры между собой. Построенные вложенные множества объектов образуют иерархию.
Иерархическая кластеризация
Инициализация:
- Каждый объект назначается отдельным
кластером. C
Итерации: B
A
- Найти два кластера с наименьшим
расстоянием между ними.
H
- Объединить два найденных кластера в D
E
новый кластер. F
G
A B D E F C G HМетоды задания расстояния между кластерами
Метод ближайшего соседа (single-link): H
E
D
F
G
Метод дальнего соседа (complete-link): H
E
D
F
G
Метод невзвешенного попарного среднего (UPGMA): H
E
D
F
G
H
Центроидный метод: E
D
F
GМетоды задания расстояния между объектами
из D'haeseleer P. How does gene expression clustering work? Nat Biotechnol. 2005, 23(12):1499-501.Визуализация результатов кластеризации
Метод кластеризации k-средних
Метод минимизирует суммарное квадратичное
отклонение объектов от центров кластеров: C
μ2
B
A
μ1
H
E
D
где k - число кластеров, Xi - кластеры F μ3
состоящие из объектов xi, - центры масс G
кластеров.
Алгоритм k-средних:
Инициализация:
Случайным образом выбрать k центров кластеров.
Итерации:
Отнести каждый объект к кластеру с ближайшим
центром.
Пересчитать положения центров кластеров.Алгоритм k-средних • Определить k случайных центров кластеров
Алгоритм k-средних • Отнести объекты к кластерам с ближайшими центрами
Алгоритм k-средних • Пересчитать положения центров кластеров
Алгоритм k-средних • Повторить до сходимости
Алгоритм k-средних • Повторить до сходимости
Классификация по Байесу • Вероятностная трактовка задачи классификации. • Построение вероятностных моделей распределений признаков объектов относящихся к различным классам. • Использование теоремы Байеса для принятия классификационного решения.
Классификация по Байесу
• Первоначально необходимо смоделировать условные плотности
вероятностей признаков для рассматриваемых классов.
P(X|Класс1) P(X|Класс2)
XКлассификация по Байесу
• Имея модели условных плотностей распределений вероятностей
признаков для классов мы сможем определить вероятность
принадлежности рассматриваемого объекта к конкретному классу
используя формулу Байеса
условная вероятность априорная вероятность
признака для данного класса объекта данного класса
вероятность признакаМоделирование P(X|класс) на основе обучающей выборки
P(X|Класс1)
• Вероятностная модель плотности
распределения может быть построена
путем разбиением области определения
на интервалы и подсчетом
соответсвующих частот.
X
7/15
3/15
2/15 2/15
1/15
XАприорные вероятности
• Три подхода к определению априорных вероятностей.
1. Оценка априорных вероятностей путем
подсчета частот классов в обучающем P(Класс1) = 12/27
множестве. P(Класс2) = 15/27
X
2. Оценка априорных вероятностей на основе
экспертных знаний. P(Класс1) = 15000/40000
P(Класс2) = 25000/40000
3. Равновероятное определение априорных
вероятностей.
P(Класс1) = P(Класс2)Классификация по Байесу
• Имея вероятностные модели условных плотностей вероятностей для
классов и априорные оценки можно определить решающее правило:
Известно: P(X|Класс1) P(X|Класс2) P(Класс1) P(Класс2)
P(X|Класс1) P(Класс1)
Решающее правило: G(X) = log
P(X|Класс2) P(Класс2)
G(X) > 0 → объект принадлежит к классу1
G(X) < 0 → объект принадлежит к классу2Наивный Байесовский классификатор • Основное предположение - независимость признаков.
Наивный Байесовский классификатор • Решающее правило:
Метод опорных векторов
(Support Vector Machines - SVM)
• Обычно существует несколько способов
признак 2
выбора прямой, разделяющей классы в
пространстве признаков.
Какую из прямых следует выбрать?
признак 1Метод опорных векторов
• В методе опорных векторов
разделительная прямая выбирается
признак 2
максимизируя расстояния (зазоры - margins)
до ближайших объектов каждого класса
(опорных векторов - support vectors).
разделительная прямая
опорные вектора
признак 1Метод опорных векторов
Пусть w - вектор, перпендикулярный
разделительной прямой.
признак 2
Тогда, уравнение разделительной прямой метки
(в многомерном пространстве - Yi = 1
гиперплоскости): Yi = -1
w·x - b = 0
разделительная прямая
Уравнение прямых, параллельных w
разделительной прямой, проходящих
через опорные вектора (с точность до
нормализации w и b):
опорные вектора
w·x - b = 1
w·x - b = -1
Присвоим метки yi принадлежности
объектов к классам равными 1 (первый
класс) и -1 (второй класс). признак 1
2/|w|Метод опорных векторов
Условия отсутствия объектов класса между прямыми, проходящими через
опорные вектора:
w·x - b >= 1 , для yi = 1
w·x - b = 1
Тогда, задача построения разделяющие гиперплоскости, максимизирующей
зазоры, сводится к следующей задаче:
|w|2 → min
yi (w·x - b) >= 1
- задача квадратичной оптимизации.Метод опорных векторов
В случае, когда классы линейно неразделимы применяют переход из исходного
пространство в пространство большой размерности - где задача может оказаться
линейно-разделимой, используя функции ядер.
Примеры ядер:
линейное
полиномиальное
радиальная базисная функция
сигмоидОценка качества классификации
Posi%ve
(Class
I) Nega%ve
(Class
II)
Признак 2
Predicted
Posi%ve True
Posi.ve
(TP) False
Posi.ve
(FP) TP
Predicted
Nega%ve False
Nega.ve
(FN) True
Nega.ve
(TN) TN
FN
FP
TP+TN
Accuracy =
TP+TN+FN+FP
TP TN
Sensitivity = Specificity =
TP+FN FP+TN Признак 1
TP
Precision =
TP+FP
Precision x Sensitivity
F1-score =
Precision + Sensitivity
Precision x Sensitivity
Fβ-score = (1+β2)
(β2·Precision) + SensitivityБлагодарности
• При подготовке слайдов использовались материалы лекций:
• Михаила Гельфанда (ИППИ)
• Андрея Миронова (МГУ)
• Serafim Batzoglou (Stanford)
• Manolis Kellis (MIT)
• Pavel Pevzner (UCSD)Вы также можете почитать

















































