Машинное обучение в HeadHunter: умный поиск соискателей и работодателей Александр Сидоров
←
→
Транскрипция содержимого страницы
Если ваш браузер не отображает страницу правильно, пожалуйста, читайте содержимое страницы ниже

Машинное обучение в
HeadHunter: умный поиск
соискателей и работодателей
Александр Сидоров
Александр Сидоров
Руководитель
анализа facebook.com
данных
al.sidorov@hh.ru
/asidorov83
HeadHunter
Кейс 1: Прескриннинг/модерация резюме
Задача • Проверять качество заполнения резюме на самом
верху воронки подбора
Проблема • Значительная часть соискателей плохо и неполно
заполняют резюме
• Использовать исторические данные по
Решение модерации резюме, чтобы автоматически
подтверждать самые качественно заполненные
Схема работы автомодерации 1. Результаты ручной модерации - исторические данные 2. Научили модель автомодерации 3. Новые резюме проверяются автомодератором 4. Качественные резюме автоматически подтверждаются 5. Спорные случаи отправляются людям >30k новых резюме в день, ↑, кол-во модераторов и качество модерации const, auc_roc 0.94 200k резюме в обучающем множестве, 1k признаков
Градиентный бустинг c xgboost • хорошо работает с разнородной информацией • не очень чувствителен к шуму • довольно чувствителен к переобучению • многопоточный, хорошая параллельность • и бинарная классификация, и регрессия • подбираем eta, n_estimators, max_depth • можно полуавтоматически, через hyperopt • «when in doubt – use xgboost» Owen Zhang, Kaggle
Dataset
Splitter
X_Valid X_Train Y_Train
Y_Valid
Categorical
Numerical Data Text Data Task
Data
Identifier
Convert to Text
Binarize
Labels Transformers
Stacker
Original PCA LDA QDA SVD
Feature Selector
Hyperparameter Selector AutoML
ML Model Selector
Evaluator xgboost – один из вариантов здесь,
нейросети «deep learning» - другой вариант
Output: Best Models with Optimized Hyperparameters
http://blog.kaggle.com/2016/07/21/approaching-almost-any-machine-learning-problem-abhishek-thakur/вся Kaggle-подобная работа здесь
Выбор признаков и
обучение моделей
Автоматическое
тестирование и
синхронный выкат
Расчёт байесовской Регулярный
Сбор априорной пересчёт Мониторинг
Оптимизация
исторических вероятности признаков и качества и
ресурсов
данных переподбор ресурсоёмкости
Расчёт признаков и моделей
работа моделей в
runtime
Работа с
эксперименталь-
ным кодом
A/B-тесты, баланс
«польза/ресурсы»Кейс 2: Подбор вакансий по резюме
• Подобрать по резюме вакансии, интересные
Задача соискателю
• Фильтр по параметрам вакансии
Решение • Машинное обучение
• Главная страница, рекомендуемые вакансии в
Функционал списке резюме, рассылки с подходящими
вакансиямиМ-a-а-ш-и-и-н-н-о-е
о-б-у-ч-е-е-н-и-и-е
Ну, нафиг… …буду экспертом
напишу формулу
вручную!Схема работы рекомендательной системы
350 000 вакансий
Эвристический фильтр 2 признака
Фильтрующая модель 1
4 признака
Фильтрующая
модель 2 26 признаков
Ранжирующая 85 признаков
модель
500-44m пар в обучающих множествах, переподбор за ночьid соискателя API для работы с БД, Java БД резюме и вакансий
PostgreSQL
резюме
Интеграционный слой, Java, Python
резюме Сервис расчёта признаков, ML pipeline, Python
Python Расчёт признаков
признаки для
резюме
Кеш признаков, Индексатор,
Cassandra Java
Frontend, nginx
признаки
соискатель
для резюме, Поиск, Java
условия поиска
Индекс с признаками для
Подбор Выгрузка
вакансий, Lucene
список моделей, и чистка
рекомендуемых Фильтрующие модели измерение данных
вакансий offline-
Ранжирующая модель метрик
Хранилище логов
A/B-тесты, Python Hadoop
Tableau Расчёт online-метрикРезультаты в откликах по результатам
A/B-тестов
+ x100 в сутки при
+ x1000 в сутки
улучшениях
при внедрениях
моделей,
там, где не было
факторов, таргетов
Иногда «просто»
уменьшаем
ресурсоёмкостьКейс 3: Ранжирование откликов
• На вакансию поступили отклики, необходимо
Задача понять кого приглашать на собеседование или
телефонное интервью
• HR-ры тратят значительное количество времени
Проблема на разбор резюме и определение списка для
собеседования
• Кнопка «Лучшие» на странице откликов на
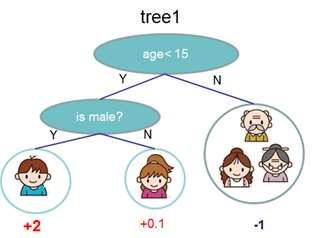
Функционал вакансиюЧеловек: делает по инструкции, учится на небольшом опыте
ошибается, субъективен, дорогое время
Неформализованный список: Дерево решений
1. Опыт работы
2. Образование ЗП > 100k
3. Навыки Нет Да
4. Зарплатные ожидания
5. … Опыт > 3 Опыт > 5
6. …
7. …
70k 60k 80k 90kМашина: учится на большом опыте
тоже ошибается, объективна, дешёвое время
1. Исторические данные: кого
пригласили на собеседование
2. Учим модель
3. Применяем модель к кандидатам
4. Улучшаем модель
Результат:
• 3,5m откликов в обучающем множестве
• 500 признаков
• 800k пар в день, 95%: 600msКейс 4: поиск по соцсетям
• Найти соискателей, у которых нет резюме или
Задача у которых они закрыты
• Собрать все профили людей, сопоставить их
Решение между собой, выделить полезное для работы
Функционал • Профили в поиске по резюмеСхема работы сопоставления профилей
365 млн. записей, 53.856 трлн. потенциальных пар
Нормализация, векторизация
Объединение в блоки 15 признаков
Попарное
сравнение 15 признаков
14k пар в обучающем множестве
точность: 99,9% - 150k пар, 80% - 4m
пересчёт за месяцРост использования машинного
обучения в рекрутинге
Модерация Ранжирование Рекомендательные Умный поиск с
резюме откликов системы MLВыводы и прогнозы Использование машинного обучения дает хороший эффект в рекрутинге: в среднем целевые метрики вырастают на десятки процентов. В краткосрочной перспективе В среднесрочной перспективе • вырастет эффективность • подбирать сотрудников и подбора за счет экономии искать работу будут ансамбли времени рекрутеров систем машинного обучения • увеличится скорость поиска с уменьшающимся участием работы для соискателей человека
17 лет меняем мир рекрутинга и HR к
лучшему!Вы также можете почитать

















































