ML & AI Обзор современных трендов - JET BI
←
→
Транскрипция содержимого страницы
Если ваш браузер не отображает страницу правильно, пожалуйста, читайте содержимое страницы ниже

ML & AI Обзор современных трендов

Введение

Что такое машинное обучение? Машинное обучение (machine learning, ML) занимается поиском скрытых закономерностей в данных Данные – набор объектов (users, images, signals, DNAs, credit histories, etc.) Объект описывается с помощью X – наблюдаемых переменных, Y – скрытых переменных Имеется лишь ограниченное число наблюдений с известными скрытыми переменными – training set Задача – найти способ предсказывать значения скрытых переменных по наблюдаемым
Пример Задача разделения на 2 класса Наблюдаемые переменные – признаки объектов (features) = =1 , ∈ ℝ2 Скрытые переменные – метки классов Y= =1 , ∈ *−1,1+ Веса W задают разделяющую гиперплоскость: = + 0
ML & AI (artificial intelligence) Эффект “new electricity” во многих областях Уже подверглись трансформации: Веб-поиск Контекстная реклама Рекомендательные системы и т.п. В начале своей трансформации: Здравоохранение Финтех Автопром Логистика

Что делает ML? Основной экономический эффект благодаря единственной идее - Supervised Learning A (input) B (response) • Email Spam? (0/1) • Image Object (1,…,1000) • Audio Text (speech recognition) • English Russian • Text Audio • Ad&User Click? Цель: выучить соответствия (A,B) по размеченным данным!

ML с точки зрения Product Manager Как правило всё, что обычный человек может сделать после

ML & AI: этапы развития (ретроспектива) • 1980-1990 гг - линейные методы для построения нелинейных решающих правил (SVM — support vector machine) • 1990-2000 гг – Байесовские модели. Вносят в модель априорную информацию. • 2000 гг – графические вероятностные модели. Сложные модели, используя простые Байесовские модели как строительные блоки. • 2000 – 2010 гг – Deep revolution. Вторая реинкарнация нейронных сетей. • 2010 гг – Big Data … • 2020 гг – AI?
ML & AI: этапы развития Big Data + AI team + HPC resources performance Large neural networks Small neural networks Traditional ML data

ML & AI: знаковые вехи • 1997: IBM Deep Blue обыграл чемпиона мира по шахматам • 2005: Беспилотный автомобтль: DARPA Grand Challenge • 2006: Google Translate - статистический машинный перевод • 2011: 40 лет DARPA CALO привели к созданию Apple Siri • 2011: IBM Watson победил в ТВ-игре “Jeopardy!” • 2011-2015: ImageNet: 25% → 3,5% ошибок 5% у людей • 2015: Фонд OpenAI в $1 млрд. Илона Маска и Сэма Альтмана • 2016: DeepMind, OpenAI: динамическое обучение играм Atari • 2016: Google DeepMind обыграл чемпиона мира по игре Го
ML & AI: Deep revolution 2006 год 2014 год
ML & AI: Deep revolution Слой 1 Слой 2 Слой 5
ML & AI: Deep revolution Обучение end-to-end всех слоев сразу: • Слои-блоки, из которых собирается сеть • Каждый слой – кусочно- дифференцируем • Градиентная оптимизация • Метод обратного распространения градиента Big gains in many domains using supervised learning
ML & AI: Deep revolution 2015
ML & AI: Deep revolution • Neural style [Gatys et al. CVPR 2016] • NB: deep learning not so strongly needed! [Ustyuzhaninov et al. ICLR 2017]
ML & AI: Deep revolution [Bahdanau et al. ICLR 2015]
ML & AI: Deep revolution AlphaGo [DeepMind, Nature’2016]
Чего не хватает, чтобы расти быстрее? Размеченные данные Face recognition: 1mln -> 15 mln -> 200 mln images! Талантливые аналитики и разработчики Адаптировать AI-алгоритмы для конкретного бизнеса
Цикл улучшения продукта с элементами AI Product with AI features Machine Learning Data Users
Горячие темы в ML & AI Распознавание речи Речевой ввод в 3 раза быстрее, чем ввод с клавиатуры Computer Vision Биометрическая идентификация путем face recognition Здравоохранение Medical imaging FinTech Понятный путь трансформации с помощью Supervised Learning
Основные понятия и обозначения
Supervised Learning X – множество объектов Y – множество ответов : → – неизвестная зависимость (target function) Дано: * 1 , … , + ⊂ – обучающая выборка (training set) = , = 1, … , – известные ответы Найти: : → – алгоритм, решающий функцию (decision function), приближающую на всём множестве X Машинное обучение – это конкретизация: • Как задаются объекты и какие могут быть ответы • В каком смысле приближает • Как строить функцию
Признаковое описание объектов : → , = 1, … , – признаки объектов (features) • = *0,1+ – бинарные • < ∞ - номинальные • < ∞, упорядочено – порядковые • = ℝ - количественные Вектор признаков 1 , … , - признаковое описание объекта Матрица “объекты-признаки” (feature data) 1 ( 1 ) … ( 1 ) ( ) = = … … … × 1 ( ) … ( )
Выходные данные и типы задач 1. Задачи классификации (classification): • = *−1, +1+ – классификация на 2 класса • = *1, … , + – на M непересекающихся классов • = 0,1 - на M непересекающихся классов 2. Задачи восстановления регрессии (regression): • = ℝ или = ℝ 3. Задачи ранжирования (ranking, learning rank): • – конечное упорядоченное множество
Модель, метод обучения Модель (predictive model) – параметрическое семейство функций = , ∈ Θ , : × Θ → Метод обучения (learning algorithm) – отображение вида : × → произвольной выборке ставит в соответствие некоторый алгоритм ∈ Этапы в Supervised Learning: • Этап обучения (training): метод по выборке строит алгоритм = ( ) • Этап применения (testing): алгоритм для новых объектов выдает ответы ( )
Примеры моделей Линейная модель с вектором параметров = 1 , … , , Θ = ℝ : • , = = =1 ( )- для регрессии и ранжирования, = ℝ • , = = =1 ( )- для классификации, = *−1, +1+ Нейросетевая модель: • , = −1 … 2 1
Функционалы качества ℒ( , ) – функция потерь (loss function) – величина ошибки алгоритма ∈ на объекте ∈ Функции потерь для задач классификации: ℒ , = , ≠ - – индикатор ошибки Функция потерь для задач регрессии: ℒ , = | − | - абсолютное значение ошибки 2 ℒ , = − - квадратичная ошибка Эмпирический риск – функционал качества алгоритма на : 1 , = ℒ( , ) =1
Сведение задачи обучения к задаче оптимизации Метод минимизации эмпирического риска: = arg min ( , ) ∈ Пример: метод наименьших квадратов ( = ℝ, ℒ квадратична): = arg min , − 2 =1 Проблема обобщающей способности: • Найдем ли мы истинную закономерность или переобучимся, т.е. подгоним функцию ( , ) под заданные точки? • Будет ли = приближать функцию на всём ? • Будет ли ( , ) мало на новых данных – контрольной выборке = ′ , ′ =1 , ′ = ?
Проблема переобучения 1 Истинная зависимость: = , “выученная” зависимость: 1+25 2 ( ) – полином степени n=38
Проблема переобучения С сточки зрения эмпирического риска, переобучение – это когда , ≫ , :
Проблема переобучения Из-за чего возникает переобучение? • Избыточная сложность пространства параметров Θ, лишние степени свободы в модели ( , ) “тратятся” на чрезмерно точную подгонку под обучающую выборку. • Переобучение есть всегда, когда есть оптимизация параметров по конечной (заведомо неполной) выборке. Как обнаружить переобучение? • Эмпирически, путем разбиения выборки на train и test Избавиться от него нельзя. Как минимизировать? • Минимизировать одну из теоретических оценок • Канладывать ограничения на (регуляризация) • Минимизировать HoldOut, LOO или CV, но оснорожно!
Типы задач в машинном обучении
Supervised Learning = обучение с учителем = обучение по прецедентам = предсказательное моделирование = проведение функции через заданные точки Классификация Регрессия
Reinforcement Learning = обучение с подкреплением Частный случай обучения с учителем, где учитель – среда или ее модель • – множество возможных действий • – множество состояний среды Агент ~ ( | ) наблюдения действия ∈ ∈ З ( +1 | , ) вознаграждение +1 ~ ( | , ) Среда
Unsupervised Learning = обучение без учителя Изветсны только описания множества объектов и требуется обнаружить внутренние взаимосвязи, существующие между объектами Примеры • Уменьшение размерности • Кластеризация данных
Predictive Learning = предвосхищающее обучение • Частный случай обучения без учителя • По заданному элементу предсказать соседние элементы (следующий, предыдущий, сопряженный и т.п.) • Не требует аннотированных данных • Особенно популярно в задачах обработки естесственного языка (NLP) Classifier CNN CNN
Прикладные задачи
Рекомендательные системы U – множество субъектов (users) I – множество объектов (items) Y – пространство описаний транзакций = , , =1 ∈ × × – транзакционные данные Агрегированные данные: = - матрица кросс-табуляции размера × , где = * , , ∈ | = , = + Задачи: • Прогнозирование незаполненных ячеек • Оценивание сходства: , ′ , , ′ , ( , ) • Формирование списка рекомендаций для или для
Рекомендательные системы Пример U – клиенты интернет-магазина, I – товары - рейтинг, который клиент u выставил товару i Задачи персонализации предложений: • выдать оценку товара i для клиента u; • выдать клиенту u список рекомендуемых товаров; • предложить совместную покупку (cross-selling); • информировать клиента о новом товаре (up-selling); • сегментировать клиентскую базу; • выделить интересы клиентов (найти целевые аудитории). Конкурс Netflix: • 2 октября 2006 – 21 сентября 2009, приз $1 млн • Точность прогнозов оценивается по тестовой выборке D’ 1 2 = ′ − 2 | | ′ , ∈
Прикладные задачи: рекомендательные системы Конкурс Netflix – результаты: • первое крупное соревнование по анализу данных — предшественник kaggle.com; • первый большой набор данных для коллаборативной фильтрации; • серьезный стимул для развития рекомендательных систем; • разработано большое количество методов коллаборативной фильтрации, некоторые из которых успешно используются до сих пор; • Netflix Prize привел к большой популярности RMSE как метрики качества рекомендаций.
Прикладные задачи: рекомендательные системы Два основных подхода к решению 1. Корреляционные модели (Memory-Based Collaborative Filtering) • хранение всей исходной матрицы данных R • сходство клиентов — корреляция строк матрицы R • сходство объектов — корреляция столбцов матрицы R 2. Латентные модели (Latent Models for Collaborative Filtering) • оценивание профилей клиентов и объектов (профиль — это вектор скрытых характеристик) • хранение профилей вместо хранения R • сходство клиентов и объектов — сходство их профилей
Прикладные задачи: рекомендательные системы Латентная модель: по данным D оцениваются векторы: ∈G - профили клиентов ∈ , ≪ | | ∈ - профили объектов i ∈ , ≪ | | Типы латентных моделей • Ко-кластеризация: = ,клиент принадлежит кластеру ∈ - -жесткая: = ,объект принадлежит кластеру ∈ - -мягкая: , - степени принадлежности кластерам • Матричные разложения: ≡ – множество тем; по , должны восстанавливаться • Вероятностные модели: ≡ – множество тем; по = , = ( | )
Прикладные задачи: рекомендательные системы Матричные разложения T – множество тем (интересов): ≪ , ≪ | | - неизвестный профиль клиента u; = ×| | - неизвестный профиль объекта ; = ×| | Задача: найти разложение = ∈ Матричная запись: = Δ , Δ = ( 1 , … , ) Вероятностный смысл: , = ∈ ( | ) Методы решения: • SVD – сингулярное разложение (плохо интерпретируется) • NNMF – неотрицательное матричное разложение: ≥ 0, ≥ 0 • PLSA – вероятностный латентный семантический анализ
Прикладные задачи: Анализ временных рядов 0 , 1 , … , , … - временной ряд, ∈ ℝ + = , ( 1 , … , ; )- модель временного ряда, где = 1, … , , - горизонт прогнозирования, w-вектор параметров модели Метод наименьших квадратов: 2 = − → min = 0 Проблемы: • Рядов может быть очень много • Решение задачи регрессии – долго • Поведение ряда может не описываться одной моделью • Функция потерь может быть не квадратичной
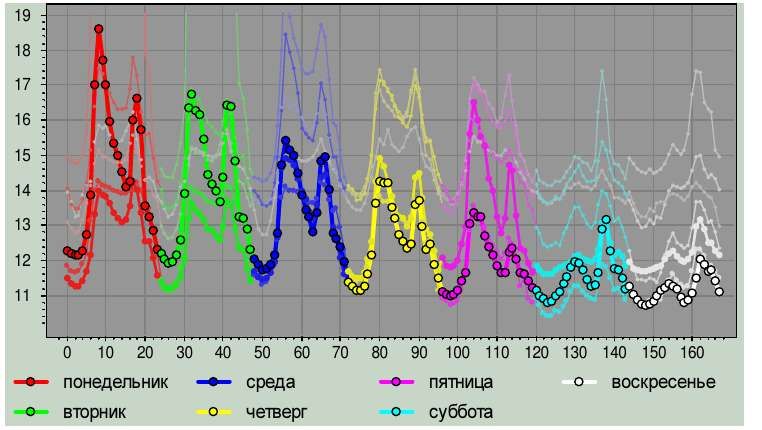
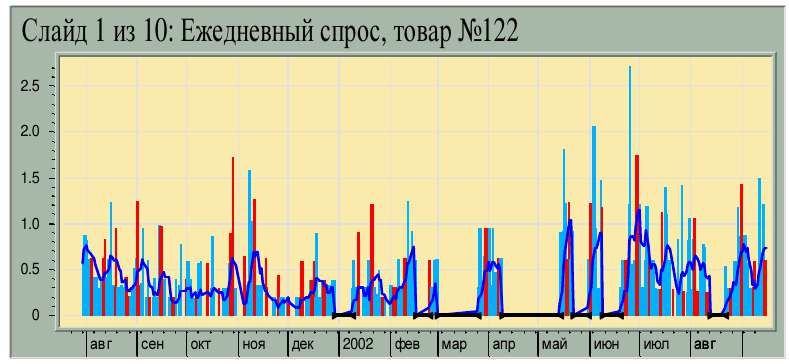
Прикладные задачи: Анализ временных рядов Объемы продаж товара Особенности: огромное число рядов, продажи зависят от типа товара, тренды, сезонность, пропуски, праздники, промоакции, скачки, плохоработают сложные модели
Прикладные задачи: Анализ временных рядов Почасовые цены электроэнергии Особенности: три вложенные сезонности, скачки
Прикладные задачи: Анализ временных рядов Методы прогнозирования • Модели авторегресси и скользящего среднего ARMA, ARIMA, GARCH, … • Нейросетевые модели • Адаптивные методы краткосрочного прогнозирования • Адаптивная авторегрессия • Адаптивная селекция моделей • Адаптивная композиция моделей • Прогнозирования плотности распределения (density forecast) • Квантильная регрессия
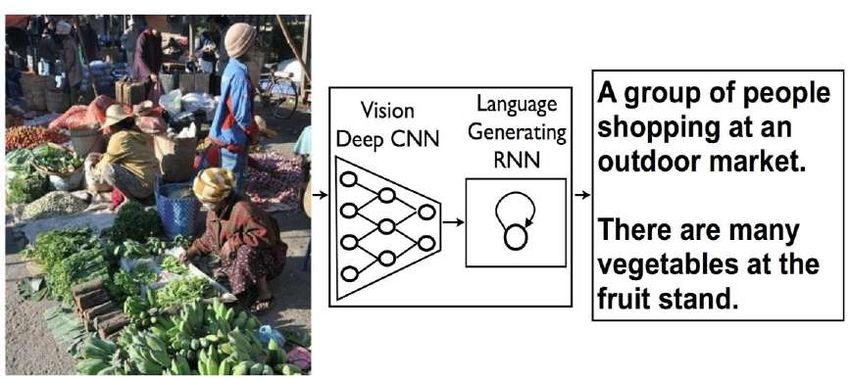
Прикладные задачи • Общение с человеком • Машинный перевод, макисмизация метрики BLEU • Генерация подписей к изображениям CIDEr
Прикладные задачи • Управление роботом, максимизация скорости операций • Видеоигры, максимизировать score • Автопилот с минимальным вмешательством человека
Прикладные задачи • Показ баннеров, максимизация кликов • Поиск страниц, макисмально релевантных запросу
Видеоигры (демо)
Вы также можете почитать

















































