ДОСТИЖЕНИЕ ВЫСОКОЙ ПРОИЗВОДИТЕЛЬНОСТИ НА GPU В ПРИЛОЖЕНИЯХ МЕТОДА ЧАСТИЦ В ЯЧЕЙКАХ - А.В.Снытников
←
→
Транскрипция содержимого страницы
Если ваш браузер не отображает страницу правильно, пожалуйста, читайте содержимое страницы ниже

ДОСТИЖЕНИЕ ВЫСОКОЙ
ПРОИЗВОДИТЕЛЬНОСТИ НА GPU
В ПРИЛОЖЕНИЯХ МЕТОДА
ЧАСТИЦ В ЯЧЕЙКАХ
А.В.Снытников
Лаборатория Параллельных Алгоритмов Решения Больших Задач
Институт Вычислительной Математики и Математической
Геофизики СО РАН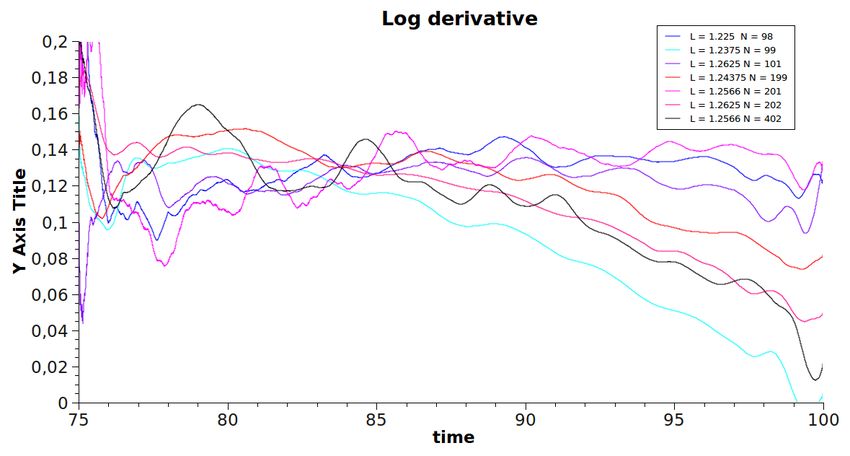
Благодарности ● Профессору, д.ф.-м.н. Б.М.Глинскому ● Профессору, д.ф.-м.н. В.А.Вшивкову ● к.т.н. А.А.Романенко
Структура доклада
● Описание решаемой физической задачи:
сложность и потребности в ресурсах
● Параллельная реализация на кластерах:
успехи и ограничения
● Реализация на GPU: преимущества метода
частиц в ячейкахЭффект аномальной
теплопроводности
● В экспериментах на установке ГОЛ-3 (ИЯФ СО РАН)
вследствие релаксации мощного электронного пучка
наблюдается понижения электронной
теплопроводности
● Коэффициент электронной теплопроводности
уменьшается в 102-103 раз по сравнению с
классическим значением для плазмы с такой
плотностью и температурой
● Это позволяет лучше нагревать плазму и дольше
удерживать ее в нагретом состоянии вследствие
намного меньшего теплового потока на стенки
установкиПереход к безразмерным
переменным
10
● скорость света c = 3x10 см/с
14
● плотность плазмы n0 = 10 см -3
● плазменная электронная частота
p = 1.6x10 сек
6 -1
2
4 n 0 e
p=
me = v , −1 = 1 −v 2
p
Основные уравнения
F = q i , e E 1 [ v , B
]
c
∂ f i ,e ∂ f i ,e ∂ f i ,e j =∑ q ∫ f
i ,e v
d v
v
F =0 i ,e
i ,e
∂t ∂x ∂v = ∑ q i ,e ∫ f i ,e d v
i ,e
1 ∂ D Начальные условия
∇ ×H =4 j e = 1000, b = 1
c ∂t
➔
= e+b
1 ∂
B
➔Импульсы электронов плазмы:
∇ ×E =− px,py,pz — максвелловское
c ∂t распределение, =Te = 1.0
2
−p
∇D =4 f =exp
➔Импульсы ионов плазмы:0
∇B =0 ➔Импульс электронов пучка:
px= 50 py= pz = 0
● Граничные условия: периодические
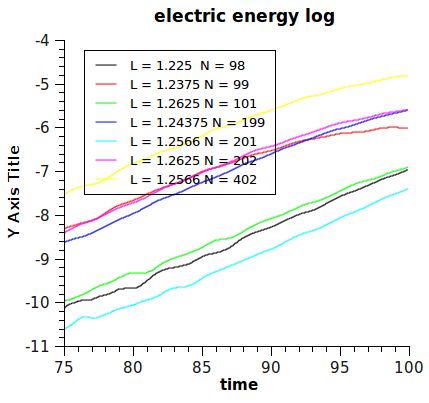
● Требуется найти: зависимость fe от времениРасчет инкрементов
∂ log E
=
∂tОценка размера задачи
● В настоящее время проведены расчеты взаимодействия
релятивистского элетронного пучка с плазмой, позволившие
в квазиодномерном случае точно рассчитать инкремент
двухпотоковой неустойчивости
● получено = 0.081, точное значение = 0.077 (Lotov et.
al., ).
● Однако для этого пришлось значительно увеличить число
модельных частиц а именно до 1000 в одной ячейке.
● Число узлов сетки 120x4x4, размер области 1.2 (в
безразмерных единицах).
●
При этом величина дебаевского радиуса 8.9x10-3 в тех же
единицах.
● Таким образом длина области в дебаевских радиусах
составляет 134.8.Оценка размера задачи
● Для адекватного моделирования плазменных неустойчивостей необходимо иметь
не менее 16 узлов сетки на длине дебаевского радиуса.
● Число модельных частиц не может быть уменьшено, иначе полученные
результаты будут носить лишь приближенный характер в известных физических
случаях (упомянутая выше двухпотоковая неустойчивость)
● В новых же физических случаях вовсе ничего невозможно будет получить.
● Задача является существенно трехмерной. В силу того, что возбуждаемые пучком
плазменные волны распространяются под углом к направлению движения пучка,
задача не может быть сведена к двумерной или одномерной без потери
существенной части физического смысла.
● Это означает, что число узлов сетки в направлениях, ортогональных направлению
движения пучка (Y и Z), должно быть сравнимым с числом узлов по направлению
X.
● Таким образом, получаем следующую оценку размера сетки: 2156х2156х2156 при
1000 модельных частиц каждого типа в ячейке.
● Это означает объем памяти 1.4 Петабайт и вычислительную нагрузку порядка 1.5
PetaFLOP (около 50 операций на каждую частицу)Моделирование плазменных неустойчивостей
требует кинетического подхода и больших
вычислительных ресурсов:
● 1000 частиц в ячейке
● Расчетная сетка (минимально) от 1003 узлов
● Скорость счета ~ 129 мегачастиц/час на ядро
● 1 млрд. частиц рассчитывается за 1 минуту на 500
ядрах (1 временной шаг из … 10000 !!!)Быстродействие памяти
Производительность кластера или резервы для оптимизации
Движение частиц
2,0
1,8
1,6
1,4 СКИФ-Cyberia
МВС-100К
время, сек
1,2
СКИФ-МГУ
1,0 Кластер НГУ
0,8
0,6
0,4
0,2
0,0
На каждом шаге для каждой частицы происходит обращение к 6 одномерным
массивам (~10 Мб каждый) и к 6 трехмерным (0.5 Мб каждый)Распределение времени работы (в %)
Кластер НГУ
90
85,44
80
70
60
50
40
30
20
10
4,52
2,39
0
движение частиц расчет температуры расчет энергииРаспределение времени работы (в %)
СКИФ-МГУ
70 66,66
60
50
40
30
23,38
20
10
3,94
0
движение частиц вычисление тока расчет температуры
Разница между движением частиц и вычислением тока
в отсутствии обращений к большим одномерным массивамОптимизация вычислений:
Идеи и методы
● Сортировка частиц
● Разбиение частиц на списки/массивы по
ячейкам
● Переупорядочивание выражений для
использования преимуществ архитектуры
компьютераВыигрыш и его цена
● Предельное ускорение в 4 раза (если
программа состоит только из интегрирования !!!)
● Сортировка: Nlog N, ~ 2 сек. на шаг для 1 млн. частиц
(слишком много... )
● D.Tskhakya: ускорение в 2 раза (списки, кэш)
● D.Anderson: 0.57 по сравнению с 1.3 сек. для 1 млн.
частиц: Cray C-90, частичное упорядочивание частиц
● Время перестановки частиц по ячейкам: для списка
0.34 сек., для статического массива < 0.1 сек.
В мировой практике было получено ускорение программы
на основе метода частиц в 2 раза
за счет упорядочивания частицИспользованные методы
оптимизации
● 6-вектор: хранение электрического и
магнитного поля в одном 4-мерном массиве
● Таблица: в 4-мерном массиве хранятся
номера частиц, принадлежащих одной
ячейке
● Список: для каждой ячейки частицы
хранятся в виде односвязного спискаОписание алгоритма
● Для каждого сорта частиц (в данном случае 2 сорта: электроны и ионы) в
каждой ячейке в целочисленном массиве длины 5N хранятся номера частиц,
находящихся в данный момент в данной ячейке.
● Номер задает позицию частицы в больших (порядка 100 млн. элементов)
вещественных массивах, в которых хранятся координаты и импульсы
модельных частиц.
● Таким образом, при перемещении частицы из одной ячейки в другую
(обязательно в соседнюю - это определяется соображениями устойчивости
метода частиц) перемещается только номер частицы
● Номер удаляется из массива номеров, описывающих текущую ячейку, и
добавляется в массив номеров одной из соседних ячеек.
● Внутри самих массивов координат и импульсов частицы никогда не
перемещаются.
● Альтернативный вариант: хранение частиц каждой ячейки в виде связанного
списка
● В обоих вариантах на вход процедуры интегрирования уравнений
движения модельных частиц подаются шесть небольших (размером не
более 5N) массивов, хранящих координаты и импульсов частиц для
каждой конкретной ячейки. Эти массивы формируются либо на основе
списка частиц, либо на основе массива номеров частиц этой ячейки.Процессор Nehalem 1.96
Расчет движения частиц, 50 частиц в ячейке
12
10
исходный
8 6-вектор
7,22
таблица
время, сек.
список
6
6-вектор/таблица
4 3,67
2
0Решение задачи в рамках традиционной кластерной архитектуры потребует (даже в минимальном варианте) очень больших (и фактически недоступных) мощностей
Переложение программы на GPU
● CUDA
● Расчет с двойной точностью: double, real*8
● Таблица частиц, рассортированных по ячейкам
● Трехмерная сетка в CUDA
● Идеи оптимизации:
● текстура,
● одномерный массив частиц: один поток — одна
частицаПрофилировка (GeForce)
Сравнение производительности
CPU vs GPU
Время счета (1 млн. частиц)
350
316
300
250
204,08
200
Производительность (GygaFLOPS)
150
25
100 79,3
50 20
2,3
0
GeForce9400 Tesla2050 Xeon Nehalem 15
10
5
0
GeForce9400 Tesla2050 Xeon NehalemИспользование текстур CUDA
● Что такое текстура: способ доступа к памяти
● Двух- или трехмерный массив с кэшированием
● Трехмерные координаты текстуры означают:
1)Номер ячейки
2)Номер частицы в ячейке
3)Атрибут частицы:
● Координаты
● Компоненты вектора импульса
● Время выполнения одного шага движения частиц (для 1
млн. частиц)
● ДляGeForce 9400 уменьшилось с 80 мс до 15.6 мс
● Для Tesla 2050 уменьшилось с 2 мс до 0.316 мсВремя счета (1 млн. частиц)
400 316
Заключение
204,08
200
15,6 0,32
0
Tesla2050 Nehalem
GeForce9400 Xeon
● Время интегрирования движения модельных частиц в
двойной точностью (тип double, real*8) с
использованием GPU происходит приблизительно в 600
раз быстрее по сравнению с расчетом в один поток на
универсальном процессоре
● Это становится возможным благодаря свойствам
метода частиц:
● Локальности данных: небольшие не связанные друг с другом
группы частиц в отдельных ячейках
● Ограниченности перемещения: частицы пролетают не более 1
ячейки за один временной шаг
● Использование гибридной архитектуры (CPU+GPU) дает
возможность провести расчеты с необходимой
точностьюВы также можете почитать